library(ggplot2)
library(purrr)
library(dplyr)
library(tidyr)
library(GGally)
library(brms)
library(projpred)
library(bayesplot)
set.seed(03072023)Exercises on Bayesian regularized regression
With these exercises, you will gain a practical understanding of different shrinkage priors and how to run a Bayesian regularized linear regression analysis using brms. In addition, we will consider the use of prior sensitivity analysis in Bayesian (regularized) analyses. Some knowledge of Bayesian analysis and familiarity with brms is assumed.
Preliminaries
First, we load several packages to run the analyses and visualize the data and results. We also set a random seed so that the results are reproducible.
Data: Abalone shells

Abalone are marine snails. Usually, the age of abalone is determined by cutting the shell, staining it, and counting the number of rings through a microscope. Adding 1.5 to the number of rings gives the age of the snail in years. In these exercises, we will try to circumvent this time-consuming task by predicting the age of abalone on alternative measurements which are easier to obtain.
The data (Nash and Ford 1995) can be downloaded here. In addition to the number of rings, which we will try to predict, the data set includes one categorical variable (Sex1) and seven continuous measurements. See the description of the data set for more details on these variables.
After you have downloaded the data and saved it in your working directory, load the data:
dat <- read.table("./abalone.data", sep = ",")
dim(dat)[1] 4177 9As you can see, the data contains 4177 observations of nine variables. To keep the computation time feasible, we will work with a subset of 100 observations for our training data.
obs.train <- sample.int(nrow(dat), size = 100, replace = FALSE)
train <- dat[obs.train, ]Before doing any analyses, it is a good idea to get familiar with your data. Although there are many different aspects you can look at (and many different ways of doing so), some things to focus on are: missing data, potential errors in the data, outliers, scales of the variables, and distributions.
head(train) V1 V2 V3 V4 V5 V6 V7 V8 V9
411 M 0.590 0.500 0.165 1.1045 0.4565 0.2425 0.3400 15
605 I 0.515 0.390 0.140 0.5555 0.2000 0.1135 0.2235 12
1558 I 0.425 0.325 0.110 0.3170 0.1350 0.0480 0.0900 8
2748 I 0.490 0.365 0.125 0.5585 0.2520 0.1260 0.1615 10
1916 F 0.600 0.470 0.135 0.9700 0.4655 0.1955 0.2640 11
2384 F 0.525 0.390 0.135 0.6005 0.2265 0.1310 0.2100 16summary(train) V1 V2 V3 V4
Length:100 Min. :0.1700 Min. :0.1050 Min. :0.0350
Class :character 1st Qu.:0.4387 1st Qu.:0.3300 1st Qu.:0.1138
Mode :character Median :0.5300 Median :0.4125 Median :0.1400
Mean :0.5091 Mean :0.3952 Mean :0.1378
3rd Qu.:0.5863 3rd Qu.:0.4662 3rd Qu.:0.1550
Max. :0.7300 Max. :0.5950 Max. :0.2300
V5 V6 V7 V8
Min. :0.0280 Min. :0.0095 Min. :0.0080 Min. :0.0050
1st Qu.:0.4121 1st Qu.:0.1675 1st Qu.:0.0900 1st Qu.:0.1237
Median :0.7380 Median :0.2978 Median :0.1653 Median :0.2152
Mean :0.7783 Mean :0.3313 Mean :0.1697 Mean :0.2189
3rd Qu.:1.0704 3rd Qu.:0.4819 3rd Qu.:0.2326 3rd Qu.:0.2863
Max. :2.8255 Max. :1.1465 Max. :0.4190 Max. :0.8970
V9
Min. : 4.00
1st Qu.: 8.00
Median :10.00
Mean :10.16
3rd Qu.:11.25
Max. :22.00 Variable 1 is actually a factor, so let’s recode it and let’s change the variable names so that they are easier to interpret:
train$V1 <- as.factor(train$V1)
colnames(train) <- c("Sex", "Length", "Diameter", "Height",
"Whole_weight", "Shucked_weight", "Viscera_weight",
"Shell_weight", "Rings")We can now visualize the data in different ways. We can, for example, consider the marginal distributions of the variables:
train %>%
ggplot(aes(Sex)) +
geom_bar()
train %>%
purrr::keep(is.numeric) %>%
gather() %>%
ggplot(aes(value)) +
facet_wrap(~ key, scales = "free") +
geom_histogram()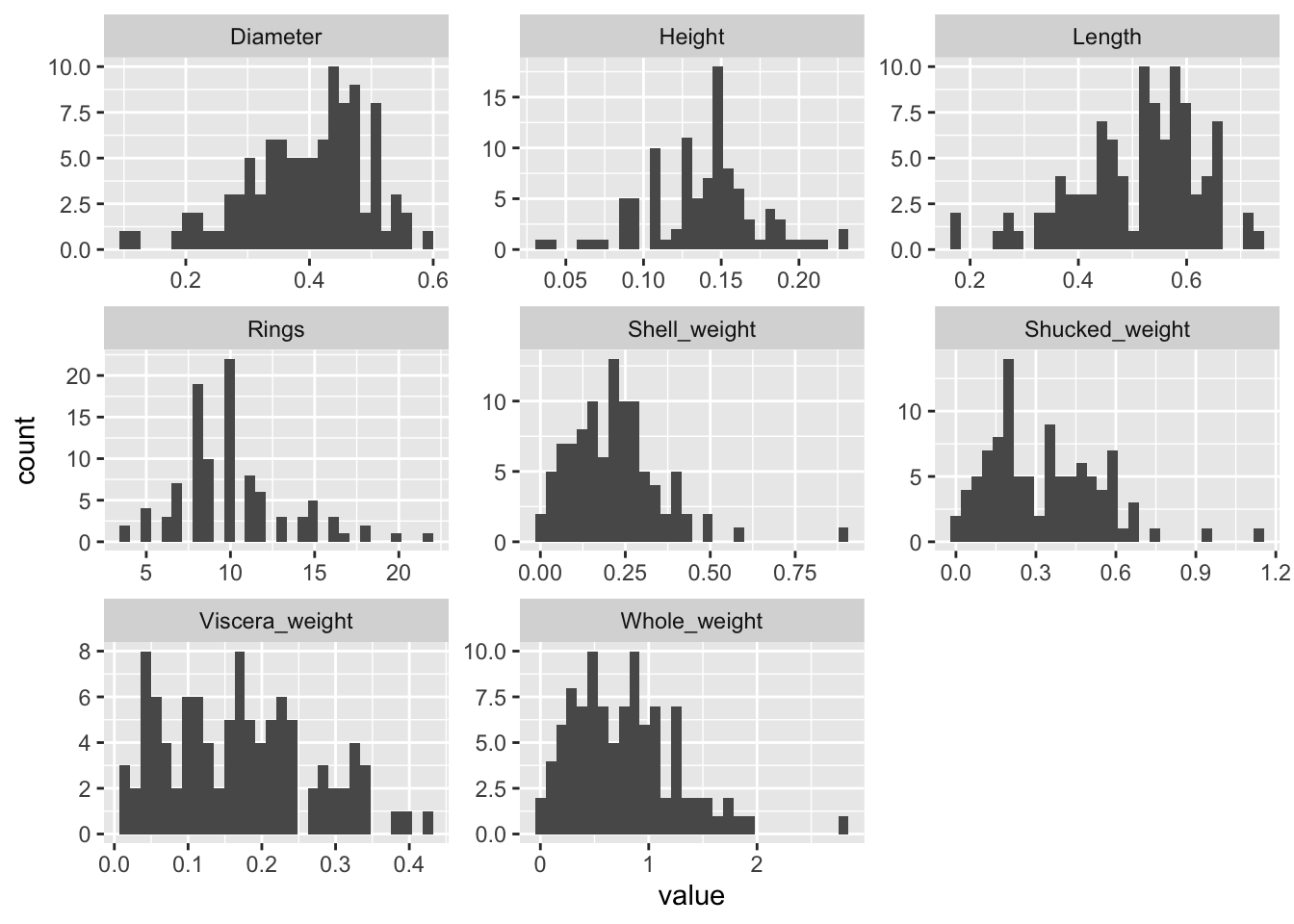
We can also visualize the bivariate relationships between variables. The code below shows paired scatterplots on the lower diagonal, correlations on the upper diagonal and marginal distributions on the diagonal.
Recreate this plot and try to colour the plots based on the categorical variable Sex (hint: you can add a colour variable via the aes() function as in a regular ggplot.
ggpairs(train)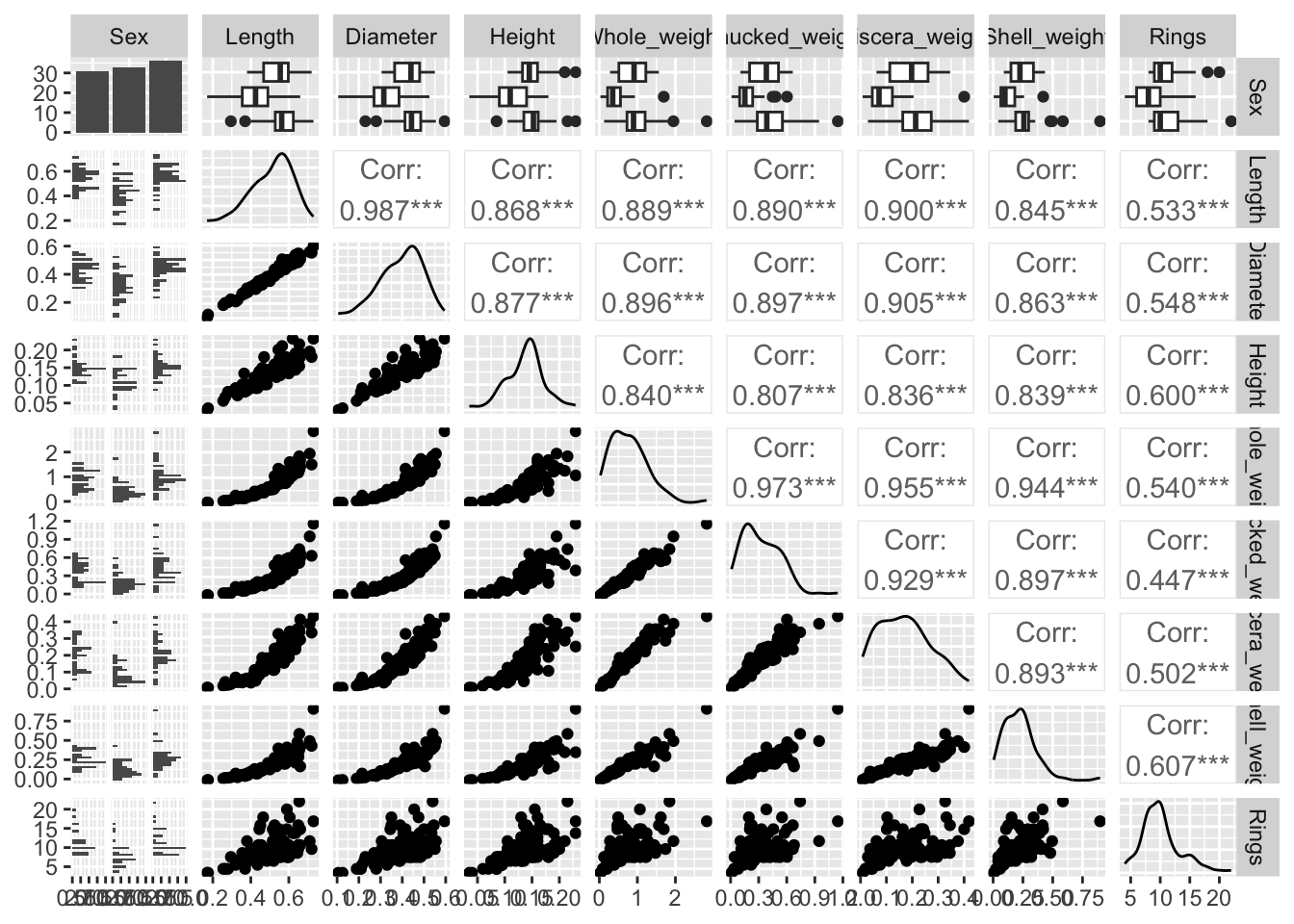
Show the code
ggpairs(train, aes(colour = `Sex`))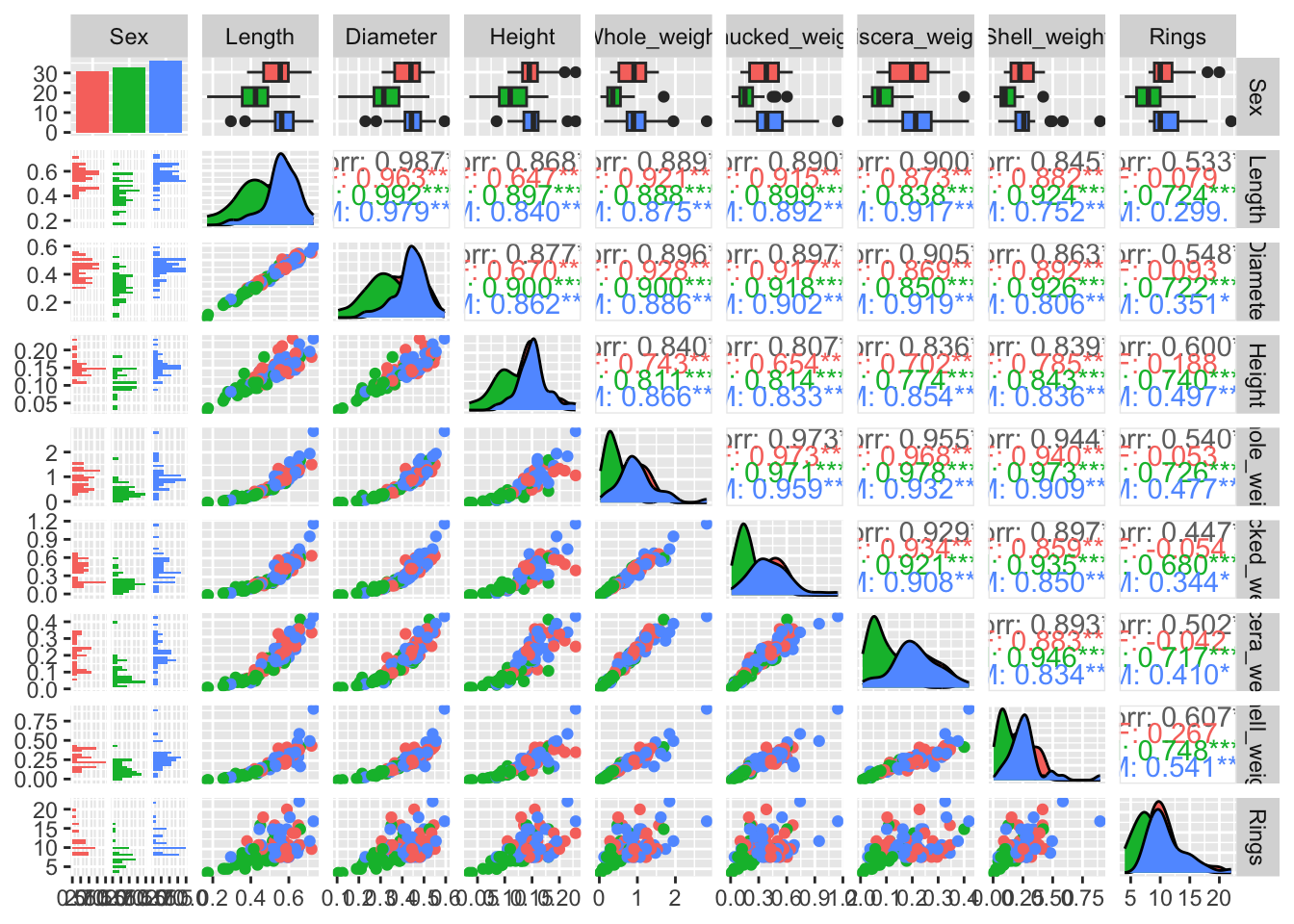
Assumptions
Since we will be running a linear regression model to predict the age of the abalone, you should check the assumptions of the model first. We will not review the assumptions of regression analysis in detail here, but some observations based on the preliminary visualizations are worth noting. First, the lower diagonal indicates some non-linear bivariate relationships. However, these exist between the independent variables rather than the independent and dependent variables so that should not be an issue. Second, correlations between the dependent variables are quite high. This multicollinearity is good to be aware of because in traditional regression analysis, this can cause the variance of the estimated regression coefficients to increase. Fortunately, one of the advantages of using regularization is that it will reduce the variance by introducing some bias. In addition to these observations, it is always a good idea to check your data for outliers since these can heavily influence the results. If variables contain observations that are theoretically impossible, these can be removed. Otherwise, it is recommended to run the analysis with and without outliers to assess the robustness of the results to the removal of outliers. Finally, in traditional linear regression analysis, it is assumed that the residuals are normally distributed with a constant variance \(\sigma^2\). This assumption underlies the Bayesian regression model as well. However, violations of this assumption are less problematic since the Bayesian framework does not rely on p-values and posterior predictive checks can be used to indicate potential violations.
Predicting the age of abalone without regularization
For reference, we will start with a Bayesian regression analysis without regularization. In this application, this is possible because we have more observations than variables in our model. However, as the number of observations per variable decreases, regularization becomes more useful to avoid overfitting and ultimately, as the number of variables exceeds the number of observations, regularization is needed to run the model (McNeish 2015). Apart from the issue of overfitting, regularization is useful to identify which variables are important in predicting the outcome, in this case: the age of abalone.
Run a regression analysis on the training data, using all variables to predict the age of abalone (i.e., the Rings variable). Use a seed value of 42 to make sure you obtain the same results. Do you recall which priors brms uses by default? How could you check which priors are being used?
Show the code
fit_default <- brm(Rings ~ ., data = train, seed = 42)
prior_summary(fit_default) We would like to select those variables that are most important in predicting abalone age. One way of doing this is by considering the 95% credible interval. This Bayesian equivalent of the classical confidence interval can be interpreted as being the interval in which the true value lies with 95% probability. If zero is included in this interval for a given predictor, we might therefore conclude that it is likely that the true effect is zero and exclude that predictor. Consider the 95% credible intervals: which predictors would you exclude and which predictors would be retained? Write this down for future reference.
Show the code
summary(fit_default)
# Selected predictors: Whole_weight, Shucked_weight, and Viscera_weightPredicting the age of abalone with regularization
We will now run the analysis with regularization. We focus on the most simple shrinkage prior possible: a normal prior with a small variance2.
In brms, the normal prior is specified with a mean and standard deviation. So if we wish to specify a prior with a variance of \(\sigma^2 = 0.01\), we should take the square root of this value (sqrt(0.01)) to obtain the standard deviation \(\sigma\). We can add the prior by adding the argument prior = prior(normal(0, 0.1) to the brm call. Run the regularized analysis and use the 95% credible intervals to decide which variables are relevant in predicting the age of abalone. Again, use a seed (542 this time) to make sure you obtain reproducible results. While you are waiting for the model to compile and sample, think about what results you would expect. Specifically, do you think we will select less or more variables compared to the previous, default analysis?
Show the code
fit_ridge <- brm(Rings ~ ., data = train,
prior = prior(normal(0, 0.1)),
refresh = 0, silent = 2,
seed = 542)Show the code
summary(fit_ridge)
# None of the variables are selectedWe have now applied a very influential shrinkage prior, resulting in a large amount of regularization. As a result, the posterior distributions are narrowly concentrated around zero. This can be seen in the summary, based on the small estimated regression coefficients and narrow credible intervals. However, an advantage of the Bayesian framework is that we can also plot the posterior distributions. With the code below we compare the posterior densities for three parameters with and without regularization. The prob argument is used to specify the shaded probability in the density. Do you see the influence of the normal shrinkage prior reflected in the plotted posterior densities?
mcmc_areas(fit_default,
pars = c("b_Diameter", "b_Whole_weight", "b_Shell_weight"),
prob_outer = 1, prob = 0.95) + xlim(-50, 75)
mcmc_areas(fit_ridge,
pars = c("b_Diameter", "b_Whole_weight", "b_Shell_weight"),
prob_outer = 1, prob = 0.95) + xlim(-50, 75)Similar plots can be created for the other parameters in the model: regression coefficients can be named using b_variable_name and the residual error standard deviation is named sigma. Consider the posterior densities for sigma across both fitobjects; are they equal? Do you expect them to be equal based on the prior distributions?
Show the code
mcmc_areas(fit_default,
pars = c("sigma"),
prob_outer = 1, prob = 0.95) + xlim(1, 4.5)
prior_summary(fit_default)
mcmc_areas(fit_ridge,
pars = c("sigma"),
prob_outer = 1, prob = 0.95) + xlim(1, 4.5)
prior_summary(fit_default)
# The posterior densities are not the same, but the priors are.
# The shrinkage prior influences the regression coefficients by
# pulling them to zero which in turn influences the residuals and
# thus the residual standard deviation, which is larger for the
# shrinkage prior.Prior sensitivity analysis: Considering various shrinkage priors
So far we have only considered a normal shrinkage prior with a small variance. This prior exerted a lot of influence on the results, pulling all regression coefficients to zero. We will now investigate a few other shrinkage priors to get a feeling of their shrinkage behaviors.
brms offers a lot of flexibility in terms of prior distributions: you can define any distribution that is available in Stan as a prior. ?set_prior offers detailed documentation and various examples. Here, we will consider two options that, in addition to the normal prior used previously, offer a variety of shrinkage behaviors:
- Student-t prior: compared to the normal prior, this prior has heavier tails and thus allows substantial coefficients to escape the shrinkage more. The heaviness of the tails is directly related to the degrees of freedom parameter
nu, with smaller degrees of freedom leading to heavier tails. - Regularized horseshoe prior: this prior can be seen as most advanced. It is very peaked at zero, but also has very heavy tails. This makes this prior especially suitable to shrink the small, irrelevant effects to zero while keeping the substantial, relevant effects large.
Before using these priors, let’s visualize them to understand their behavior a bit better. First, we need draws from the prior distributions. To obtain these, we run brms using the argument sample_prior = "only". This will result in a fit object containing only draws from the prior distribution. Use the code below to sample from the three shrinkage priors.
prior_t <- brm(Rings ~ ., data = train,
prior = set_prior("student_t(3, 0, 0.1)", class = "b"),
sample_prior = "only",
refresh = 0, silent = 2, seed = 786)
prior_hs <- brm(Rings ~ ., data = train,
prior = set_prior(horseshoe(df = 1, scale_global = 1,
df_global = 1, scale_slab = 2,
df_slab = 4, par_ratio = NULL,
autoscale = TRUE), class = "b"),
sample_prior = "only",
refresh = 0, silent = 2, seed = 146)Next, you can use the mcmc_areas function to plot the prior distributions for specific parameters. However, it can be more insightful to plot the prior distributions together in one figure. To do this, we first need to combine the prior draws. Then, we can plot the prior for a specific regression coefficient, for example b_Height:
draws_t <- as_draws_df(prior_t)
draws_t$prior <- "t"
draws_hs <- as_draws_df(prior_hs)
draws_hs$prior <- "hs"
sel <- c("b_SexI", "b_SexM", "b_Length", "b_Diameter", "b_Height",
"b_Whole_weight", "b_Shucked_weight", "b_Viscera_weight",
"b_Shell_weight", "prior")
draws <- rbind.data.frame(draws_t[, sel],
draws_hs[, sel])
ggplot2::ggplot(draws, aes(b_Height, colour=prior)) +
geom_density() +
xlim(-5, 5) +
theme_minimal()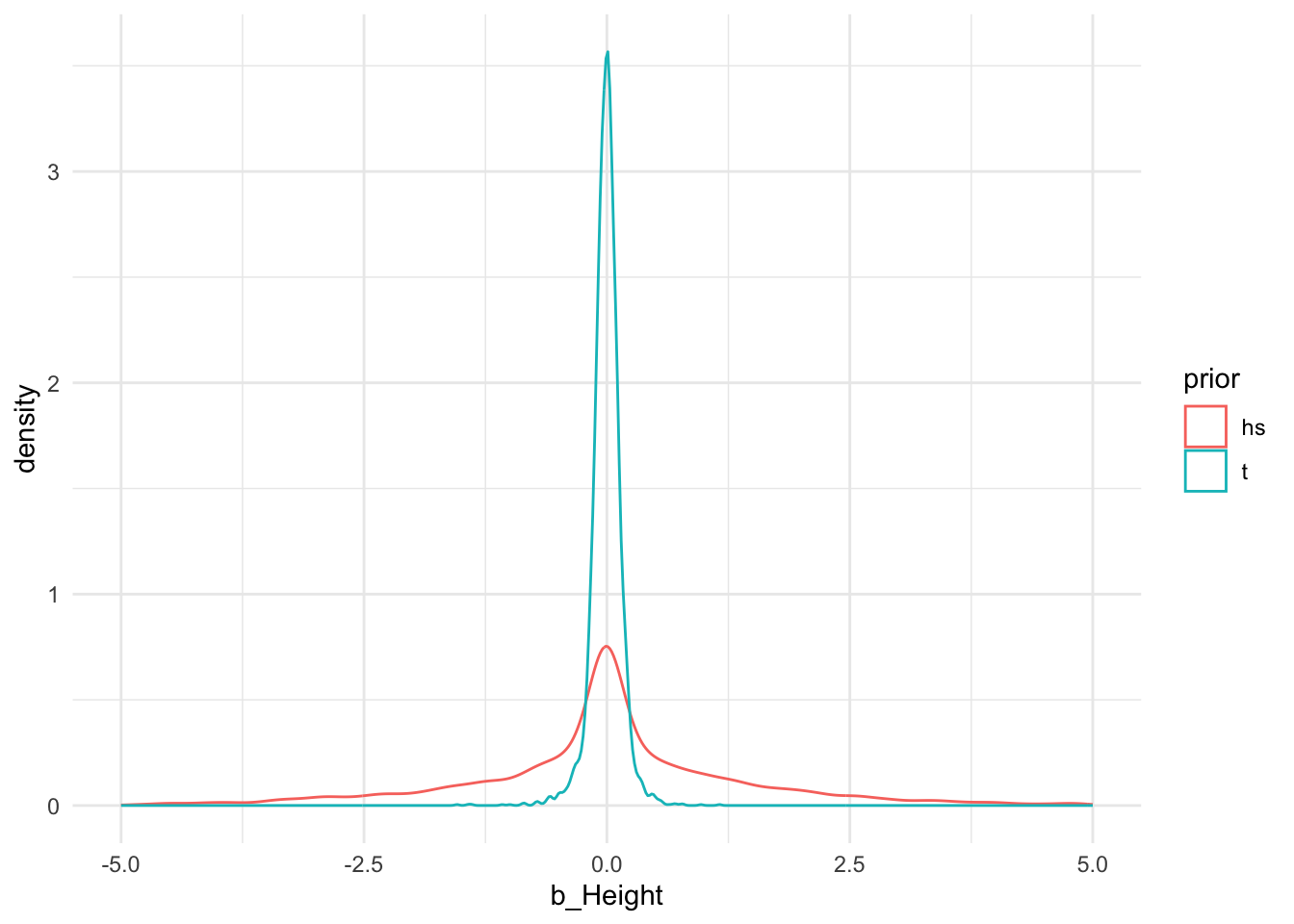
This way, we can compare different parametric forms and see, for example, that with these settings Student’s t prior has much lighter tails than the horseshoe prior.
We can also adapt the hyperparameters of each prior. For the next exercise, adapt the hyperparameters of the Student’s t prior. Consider three or four different settings. Note that the location of the prior should remain at zero to ensure shrinkage towards zero, however, you can change both the degrees of freedom and the scale of the prior. Visualize the prior for different hyperparameter settings and try to reason whether you would expect different results in terms of shrinkage towards zero and, ultimately, variable selection. In addition to visualizing the prior distribution itself, you can also perform prior predictive checks and visualize possible distributions of data generated for a specific data set (see day 3).
Comparing results across different priors
Now that we have a good idea of the different shrinkage prior distributions, we can run the analysis for different prior specifications and compare the outcome of interest, in our case: the selection of variables to predict abalone age. Run the analysis with the original Student’s t and horseshoe priors specified above. You can also add one or more of the priors you investigated yourself.
Compare the amount of shrinkage, for example by looking at the estimated regression coefficients or the full posteriors, as well as the number of selected variables based on the 95% credible intervals. Do the results differ across different shrinkage priors and are the differences in line with your intuition regarding the shrinkage behaviors of the priors?
Show the code
fit_t <- brm(Rings ~ ., data = train,
prior = set_prior("student_t(3, 0, 0.1)", class = "b"),
seed = 786)
# Indicates no relevant variables (like the ridge), but note the increased uncertainty (caused by a bimodal posterior) for Whole_weight
fit_hs <- brm(Rings ~ ., data = train,
prior = set_prior(horseshoe(df = 1, scale_global = 1,
df_global = 1, scale_slab = 2,
df_slab = 4, par_ratio = NULL,
autoscale = TRUE), class = "b"),
seed = 146)
# Also selects no variables, but note how the credible intervals show more uncertainty for some variables, especially the weight variables
# Visualize differences in the posteriors
draws_ridge <- as_draws_df(fit_ridge)
draws_ridge$prior <- "ridge"
draws_t <- as_draws_df(fit_t)
draws_t$prior <- "t"
draws_hs <- as_draws_df(fit_hs)
draws_hs$prior <- "hs"
sel <- c("b_SexI", "b_SexM", "b_Length", "b_Diameter", "b_Height",
"b_Whole_weight", "b_Shucked_weight", "b_Viscera_weight",
"b_Shell_weight", "prior")
draws <- rbind.data.frame(draws_ridge[, sel],
draws_t[, sel],
draws_hs[, sel])
draws_long <- gather(draws,
key = "parameter",
value = "value",
-prior)
ggplot(draws_long, aes(value, colour=prior)) +
geom_density() +
facet_wrap(~ parameter, scales = "free") +
theme_minimal()
Note
Note that we do get some warnings related to convergence. For the final results, it is important to assess convergence to ensure trustworthy results. In case of low effective sample sizes, you can rerun the analysis with more iterations. Note that the horseshoe prior can also result in divergent transitions, which are more difficult to resolve. When the horseshoe prior is one of the options in a prior sensitivity analysis, like here, this might not be as big an issue since we do not use these results for final interpretation but only for comparison.
Did we forget anything?
So far, we have done a lot: we have investigated different shrinkage priors and compared their influence in predicting abalone age. We have seen that different types of shrinkage priors have different prior densities which result in different shrinkage behaviors and ultimately, different results. However, as you considered the potential influence of the shrinkage priors you might already have wondered about the role that the scales of the variables play. This is actually a very important point in Bayesian analysis in general, and even more so in Bayesian regularization in particular. The scale of the variables will influence the plausible parameter space of the regression coefficients and this will influence the informativeness of the prior distribution. To illustrate this, consider one variable in our data set, the Length of the shells. In this data set, Length is measured in millimeter and if we use this variable in a simple linear regression to predict the abalone age, we get an estimated regression coefficient of 15.6.
fit <- lm(Rings ~ Length, data = train)
summary(fit)
Call:
lm(formula = Rings ~ Length, data = train)
Residuals:
Min 1Q Median 3Q Max
-3.5792 -1.9153 -0.8852 1.5569 9.5617
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.207 1.306 1.689 0.0944 .
Length 15.621 2.503 6.240 1.12e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.869 on 98 degrees of freedom
Multiple R-squared: 0.2844, Adjusted R-squared: 0.2771
F-statistic: 38.94 on 1 and 98 DF, p-value: 1.117e-08We can view this estimate as the general, unregularized estimate so using flat priors. You can check this by running the same analysis with brms and its default priors.
Show the code
fit <- brm(Rings ~ Length, data = train, seed = 387)
summary(fit)Now consider a normal shrinkage prior with a standard deviation of \(\sigma = 10\). This prior looks like this:
plot(density(rnorm(100000, 0, sd = 10)))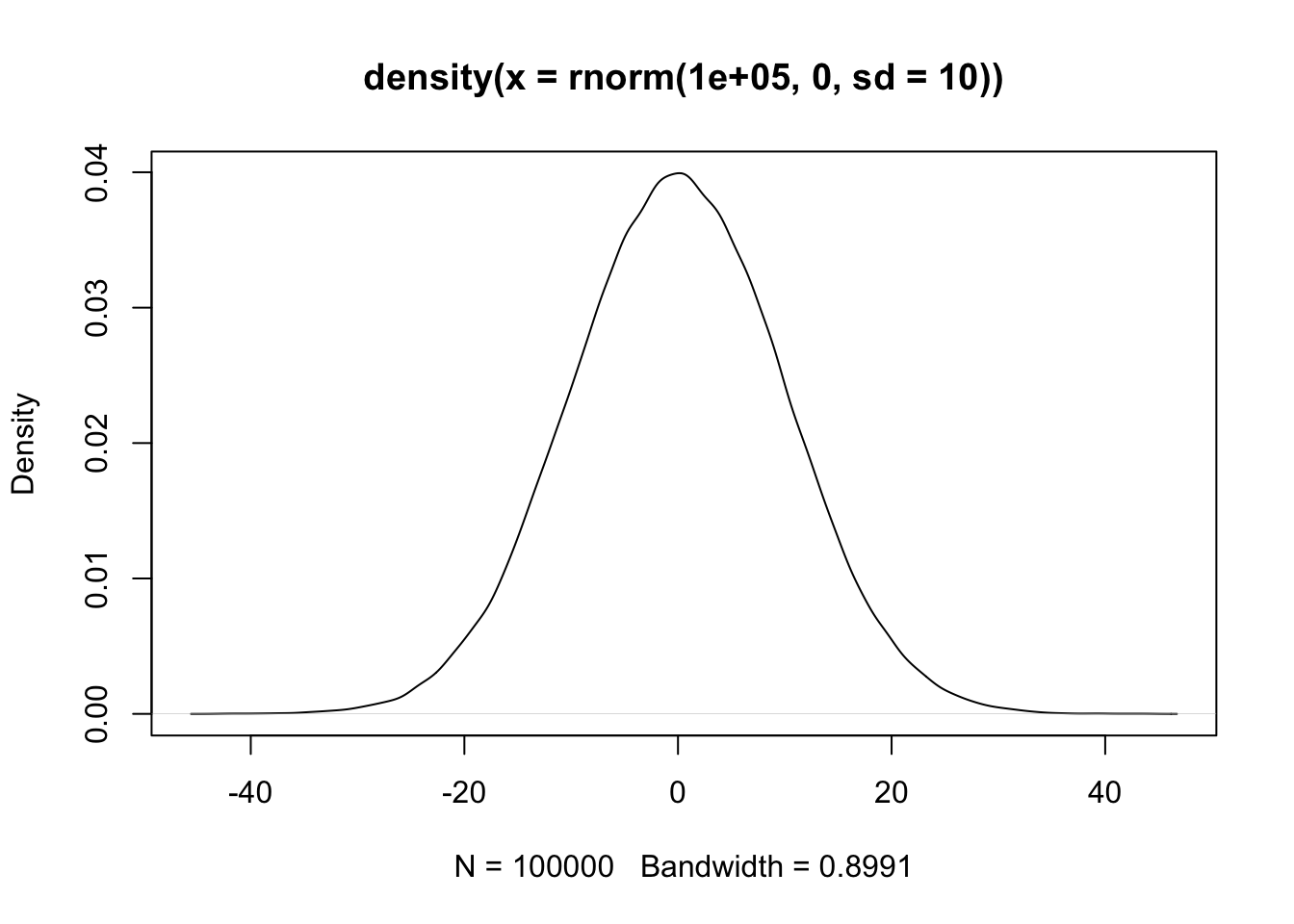
You can see that most of the prior mass lies between -20 and 20. How much influence do you think this prior will exert on the regression coefficient of Length, that is estimated to be around 15 when using flat priors? You can check your intuition by running the analysis.
Show the code
fit <- brm(Rings ~ Length, data = train,
prior = set_prior("normal(0, 10)", class = "b"),
seed = 156)
summary(fit)
# There is practically no influence of this prior; it is relatively uninformative given the scale of the variable.Suppose that Length was measured in centimeters instead of millimeters. Let’s create a new variable, Length_cm:
train_new <- train
train_new$Length_cm <- train_new$Length/10Run the analysis again, but now with the length measured in centimeters as predictor. First run a classical regression model to check the size of the effect without any regularization or shrinkage due to the prior and then run the model with the normal(0, 10) prior.
Show the code
fit1 <- lm(Rings ~ Length_cm, data = train_new)
summary(fit1)
fit2 <- brm(Rings ~ Length_cm, data = train_new,
prior = set_prior("normal(0, 10)", class = "b"),
seed = 928)
summary(fit2)
# Now, the effect is shrunken heavily!Now, our normal(0, 10) prior is much more informative!
You can imagine that if we have variables measured on different scales, say one variable in cm and another in mm, that specifying one common shrinkage prior (or even a prior in general) is not a good idea because the informativeness of the prior, and thus the amount of shrinkage, will depend on the scale of the variable. Therefore, it is highly recommended to always standardize your variables before applying regularization. This makes it easier to specify one general shrinkage prior for all coefficients.
Rerun the analysis with the horseshoe prior but this time first scaling the data.
Show the code
train_scaled <- data.frame(scale(train[, -1], center = TRUE, scale = TRUE))
train_scaled$Sex <- train$Sex
fit_hs_scaled <- brm(Rings ~ ., data = train_scaled,
prior = set_prior(horseshoe(df = 1, scale_global = 1,
df_global = 1, scale_slab = 2,
df_slab = 4, par_ratio = NULL,
autoscale = TRUE), class = "b"),
refresh = 0, silent = 2, seed = 115)
summary(fit_hs_scaled)
# Now, we would select Shell_weight and Shucked_weight based on the 95% CI!
mcmc_areas(fit_hs, pars = c("b_Shell_weight", "b_Shucked_weight"), prob = 0.95, prob_outer = 1)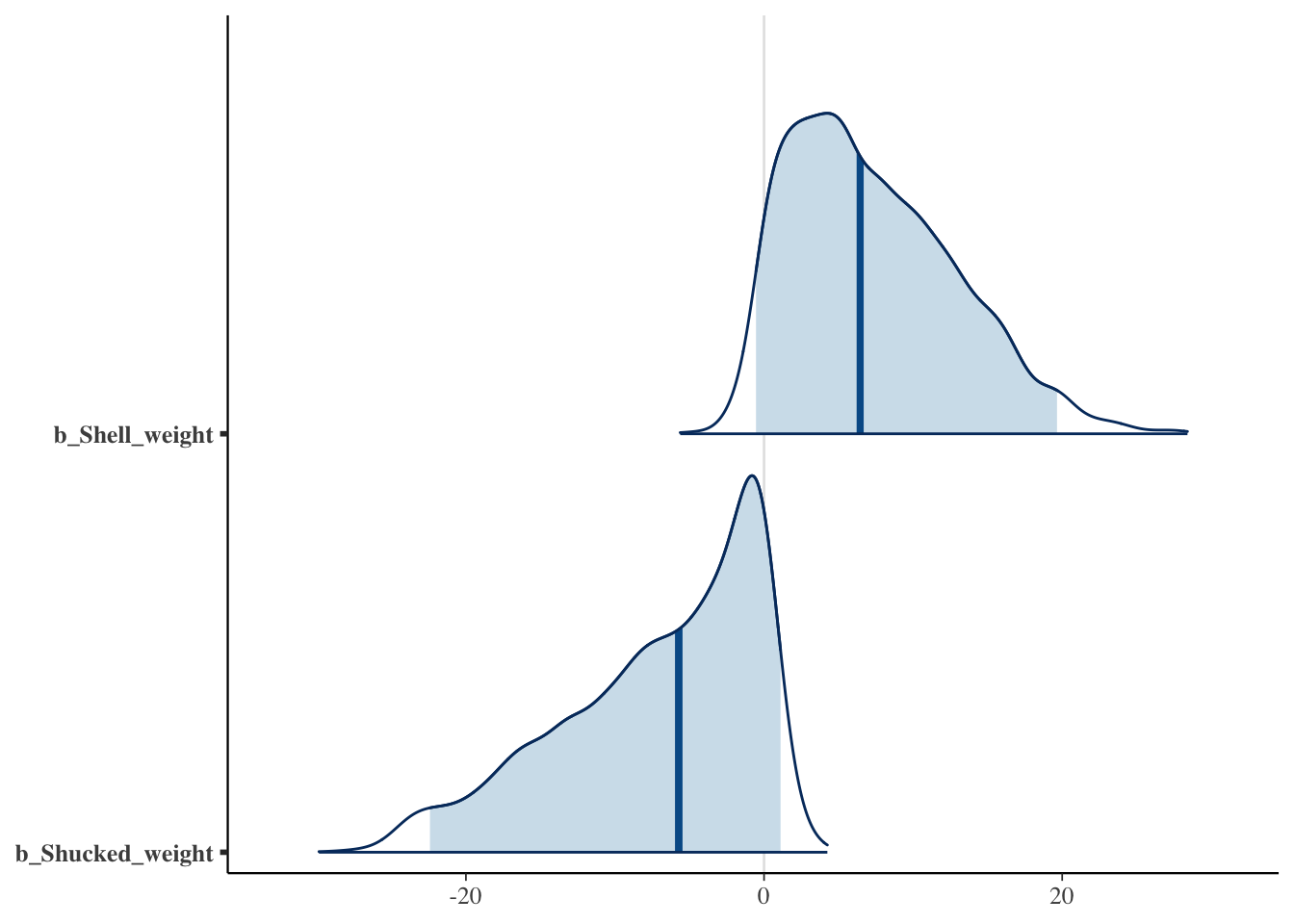
Show the code
mcmc_areas(fit_hs_scaled, pars = c("b_Shell_weight", "b_Shucked_weight"), prob = 0.95, prob_outer = 1)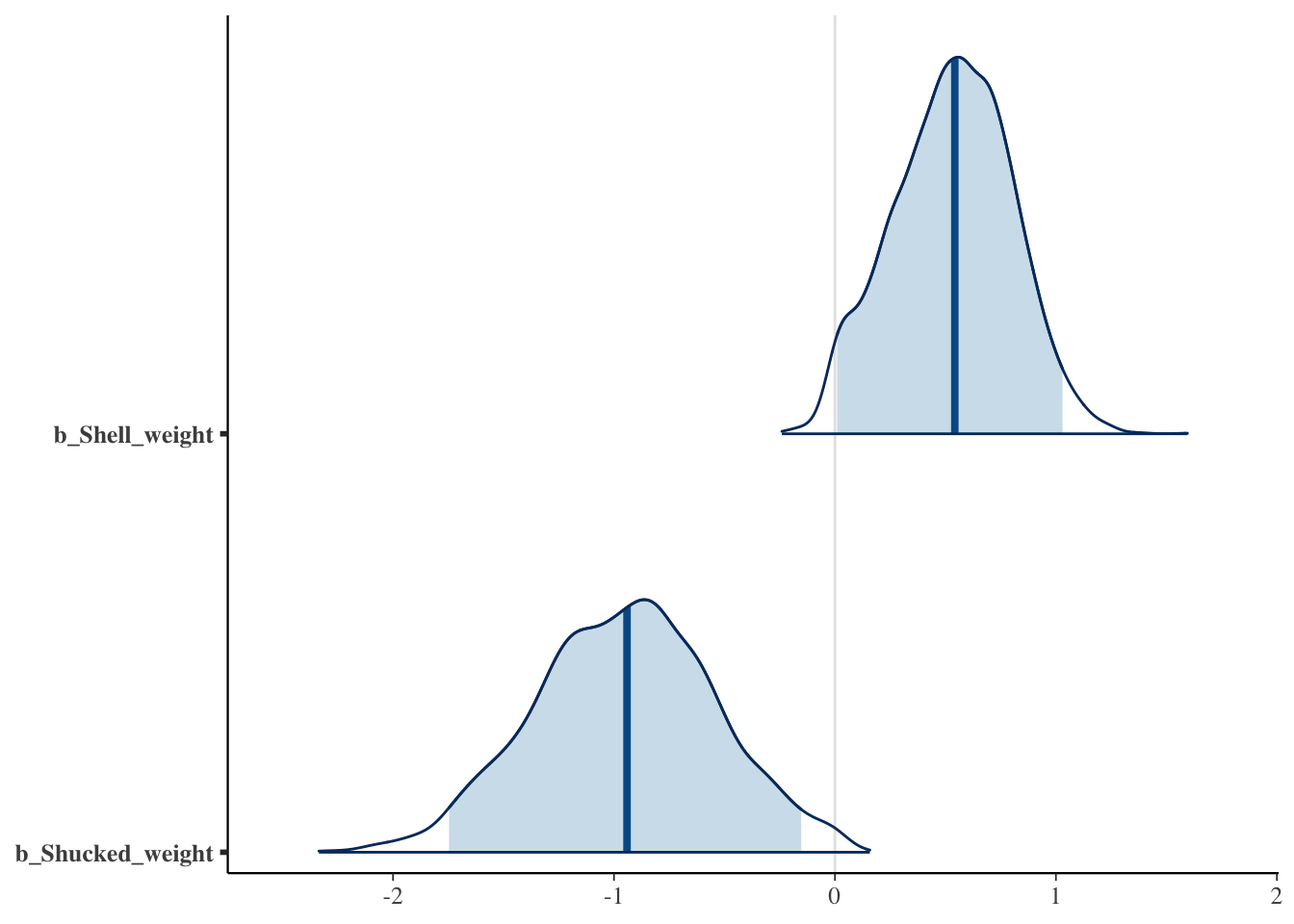
Intermediate summary
So far, we have conducted a Bayesian regularized regression analysis to predict the age of abalone. We started with a simple normal prior (also called a ridge prior) and noted that this prior heavily pulled all variables toward zero. Next, we considered a Student’s t prior and horseshoe prior which showed slightly different shrinkage behaviors for some variables. However, throughout this process, we forgot one very important thing that we should always consider in a Bayesian analysis: the scale of our variables! If we had been more careful in our prior specification (see also the WAMBS checklist from day 2), we would probably have figured out that our normal shrinkage prior is more informative for some variables compared to others given the differing scales. Whenever this is the case, either specify separate priors for each regression coefficient that depend on the scale of the coefficient or scale the variables before the analysis.
Projection predictive variable selection
One of the main goals of our analysis is to select which variables are important in predicting the age of abalone. In traditional regularized regression, a penalty such as the lasso is able to set regression coefficients to exactly zero. However, in the Bayesian framework where we rely on posterior summary statistics such as the mean or median, regularized estimates will never be exactly zero. We thus need an additional step to perform variable selection. Up until now, we have used the marginal 95% credible interval to do so, but there are alternatives. One alternative would be to use a cut-off for the estimate, for example 0.1 and select a parameter if its regression coefficient exceeds this value. However, as you can imagine, the choice of cut-off value is rather arbitrary. Actually, the credible interval criterion we have considered thus far is also a rather arbitrary criterion: why use the 95% interval and not the 94% interval? Or the 88.8% interval?3
An alternative variable selection method is projection predictive variable selection. The basic idea behind this method is that the best possible prediction will be obtained when all variables are used. However, this model is not very parsimonious so we use this model as a reference and then look for a simpler model that gives similar answers to the full model in terms of predictive ability. By doing so, a more parsimonious model is obtained.4
The projection predictive method is implemented in the projpred package. To perform the variable selection, two functions can be used: varsel and cv_varsel. The latter function performs cross-validation by first searching for the best submodel given a specific number of predictors on a training set and subsequently evaluating the predictive performance of the submodels on a test set. This cross-validation approach is recommended over varsel to avoid overfitting. However, cv_varsel is also much slower compared to varsel, so for the purpose of these exercises we will rely on the faster varsel function.
We will run the variable selection for the scaled model with the horseshoe prior. We then obtain the optimal model size and check which predictors should be included given this optimal model size.
vs <- varsel(fit_hs_scaled, seed = 364)
nsel <- suggest_size(vs)
ranking(vs, nterms_max = nsel)$fulldata
[1] "Shell_weight" "Shucked_weight" "Height" "Sex"
[5] "Whole_weight" "Diameter" "Viscera_weight"
$foldwise
NULL
attr(,"class")
[1] "ranking"Note that the suggest_size function is easy to use, but: it provides only a heuristic for determining optimal model size. A better approach is to plot a performance statistic, which can be easily done as follows:
plot(vs)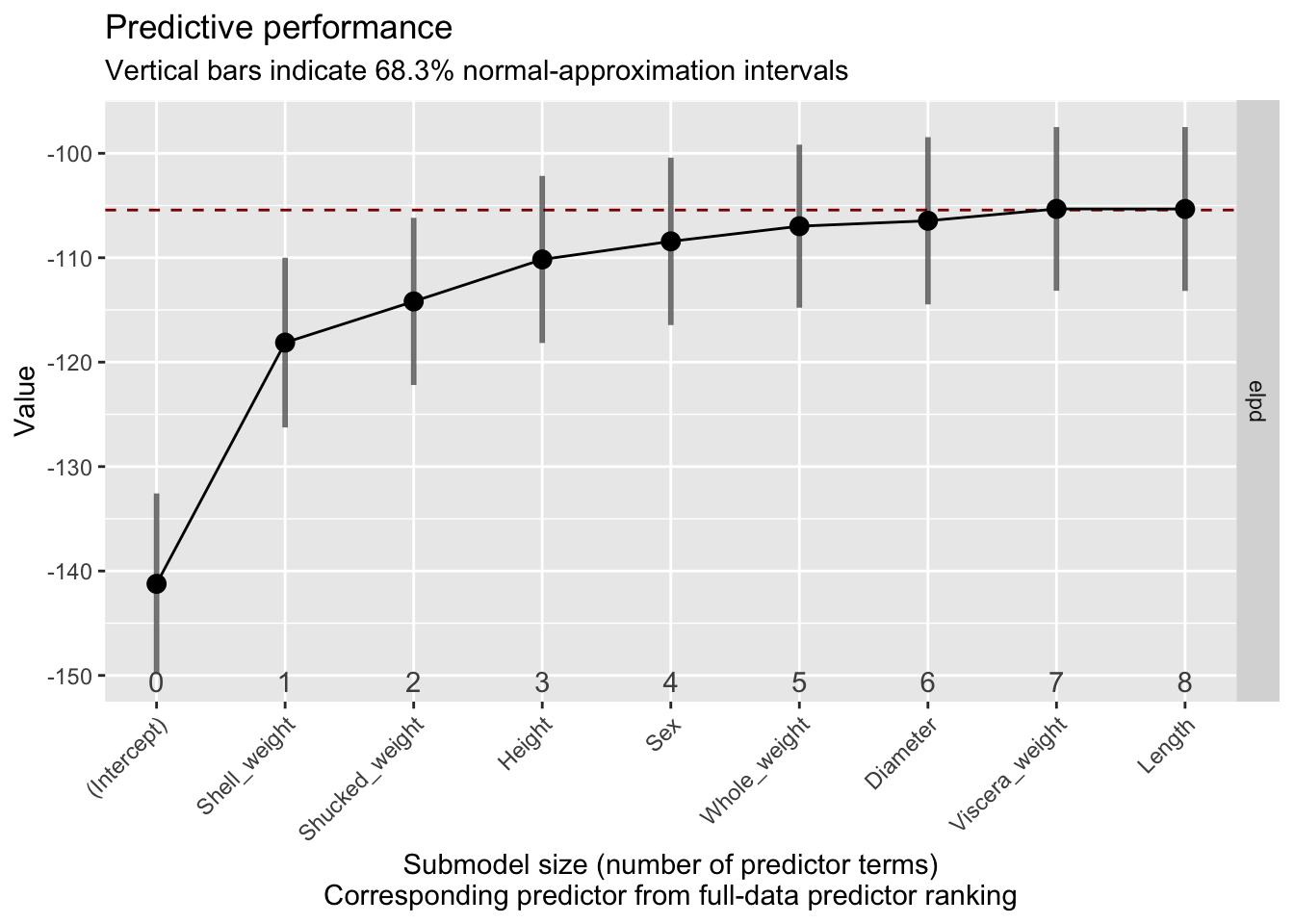
By default, elpd, the expected log predictive density is plotted. The important thing to consider is when this value levels off: that indicates that the performance does not change as we include more predictors. The dashed line indicates the predictive performance of the reference model, so the model including all predictors. Based on this plot we can conclude that we can obtain sufficient predictive performance with five or six predictors, a bit less than suggested by the suggest_size function.
Now, compare the selected variables to those selected using the other shrinkage priors we considered in the sensitivity analysis. Are there big differences? Do the selected variables differ greatly from those selected based on the 95% credible intervals?
Going beyond variable selection: Evaluating the model
So far, we have focused solely on determining the number of variables to select and assessing whether this number varies when using different shrinkage priors or different selection criteria. Before performing variable selection, we can also consider how well our model fits the data, for example by considering a posterior predictive check.
Perform a visual posterior predictive check for the scaled model after regularization with the horseshoe prior.
Show the code
ppc <- pp_check(fit_hs_scaled, ndraws = 100)
plot(ppc)You could also assess the final model, after variable selection. To do so, rerun the analysis using only the variables Shell_weight, Shucked_weight, Height, and Sex. Make sure you do not use shrinkage priors this time; we have already used the shrinkage to select the variables, now we simply want to estimate the effects of the selected variables without shrinkage. Perform a posterior predictive check. Do we still get sensible results?
Show the code
fit_sel <- brm(Rings ~ Shell_weight + Shucked_weight + Height + Sex, data = train_scaled, seed = 444)
ppc_sel <- pp_check(fit_sel, ndraws = 100)
plot(ppc_sel)As we have seen in yesterday’s practical, it is a good idea to not only consider how close data generated based on the posterior is to the training data, but also to new, unseen test data.
# Sample 50 test observations from the original data
obs.all <- 1:nrow(dat)
unseen <- obs.all[! obs.all %in% obs.train]
obs.test <- sample(unseen, size = 50, replace = FALSE)
test <- dat[obs.test, ]
test$V1 <- as.factor(test$V1)
colnames(test) <- c("Sex", "Length", "Diameter", "Height",
"Whole_weight", "Shucked_weight", "Viscera_weight",
"Shell_weight", "Rings")Perform a posterior predictive check on the unseen test data with only the selected predictors. What can you conclude?
Show the code
# Make sure you first scale the test data too, otherwise you are using a model fit
# on scaled data to predict unscaled data which will lead to very bad predictions
test_scaled <- data.frame(scale(test[, -1], center = TRUE, scale = TRUE))
test_scaled$Sex <- test$Sex
pp_check(fit_sel, type = "dens_overlay", prefix = "ppc", ndraws = 100,
newdata = test_scaled)
# This quick check looks quite good; we seem to predict ok even with just these 4 predictorsRecap
In these exercise, you have seen the effects of different shrinkage priors in a Bayesian regularized linear regression analysis and compared different ways of selecting variables. Ultimately, the goal of the analysis is to decide which variables are important in predicting a certain outcome but also to be confident that the results are robust. The prior sensitivity analysis can help in this regard although it is important to note that in some cases, results will differ across different shrinkage priors. This illustrates the importance of understanding your prior and the influence it has on the results. So make sure you think carefully about your (shrinkage) prior distribution; make sure you understand it and its influence on the results; and report your results in a transparent manner.
Further exercises
The best way to consolidate your understanding of these methods is to practice. So download some data online (for example from the UC Irvine Machine Learning Repository) or use your own data and apply the methods. From here it would be especially interesting to look at data with a larger number of predictors or a binary outcome. The latter requires you to run a regularized logistic regression model. You can do so in brms by specifying family = bernoulli(link = "logit").
Original computing environment
devtools::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.1 (2025-06-13)
os macOS Sequoia 15.5
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Amsterdam
date 2025-07-16
pandoc 3.2 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/aarch64/ (via rmarkdown)
quarto 1.5.57 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
abind 1.4-8 2024-09-12 [1] CRAN (R 4.5.0)
backports 1.5.0 2024-05-23 [1] CRAN (R 4.5.0)
bayesplot * 1.13.0 2025-06-18 [1] CRAN (R 4.5.0)
bridgesampling 1.1-2 2021-04-16 [1] CRAN (R 4.5.0)
brms * 2.22.0 2024-09-23 [1] CRAN (R 4.5.0)
Brobdingnag 1.2-9 2022-10-19 [1] CRAN (R 4.5.0)
cachem 1.1.0 2024-05-16 [1] CRAN (R 4.5.0)
checkmate 2.3.2 2024-07-29 [1] CRAN (R 4.5.0)
cli 3.6.5 2025-04-23 [1] CRAN (R 4.5.0)
coda 0.19-4.1 2024-01-31 [1] CRAN (R 4.5.0)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.1)
colorspace 2.1-1 2024-07-26 [1] CRAN (R 4.5.0)
devtools 2.4.5 2022-10-11 [1] CRAN (R 4.5.0)
digest 0.6.37 2024-08-19 [1] CRAN (R 4.5.0)
distributional 0.5.0 2024-09-17 [1] CRAN (R 4.5.0)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.5.0)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.5.0)
evaluate 1.0.4 2025-06-18 [1] CRAN (R 4.5.0)
farver 2.1.2 2024-05-13 [1] CRAN (R 4.5.0)
fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.5.0)
fs 1.6.6 2025-04-12 [1] CRAN (R 4.5.0)
generics 0.1.4 2025-05-09 [1] CRAN (R 4.5.0)
GGally * 2.2.1 2024-02-14 [1] CRAN (R 4.5.0)
ggplot2 * 3.5.2 2025-04-09 [1] CRAN (R 4.5.0)
ggstats 0.10.0 2025-07-02 [1] CRAN (R 4.5.0)
glue 1.8.0 2024-09-30 [1] CRAN (R 4.5.0)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.5.0)
gtable 0.3.6 2024-10-25 [1] CRAN (R 4.5.0)
htmltools 0.5.8.1 2024-04-04 [1] CRAN (R 4.5.0)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.5.0)
httpuv 1.6.16 2025-04-16 [1] CRAN (R 4.5.0)
inline 0.3.21 2025-01-09 [1] CRAN (R 4.5.0)
jsonlite 2.0.0 2025-03-27 [1] CRAN (R 4.5.0)
knitr 1.50 2025-03-16 [1] CRAN (R 4.5.0)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.5.0)
later 1.4.2 2025-04-08 [1] CRAN (R 4.5.0)
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.1)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.5.0)
loo 2.8.0 2024-07-03 [1] CRAN (R 4.5.0)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.5.0)
Matrix 1.7-3 2025-03-11 [2] CRAN (R 4.5.1)
matrixStats 1.5.0 2025-01-07 [1] CRAN (R 4.5.0)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.5.0)
mime 0.13 2025-03-17 [1] CRAN (R 4.5.0)
miniUI 0.1.2 2025-04-17 [1] CRAN (R 4.5.0)
mvtnorm 1.3-3 2025-01-10 [1] CRAN (R 4.5.0)
nlme 3.1-168 2025-03-31 [2] CRAN (R 4.5.1)
pillar 1.11.0 2025-07-04 [1] CRAN (R 4.5.0)
pkgbuild 1.4.8 2025-05-26 [1] CRAN (R 4.5.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.5.0)
pkgload 1.4.0 2024-06-28 [1] CRAN (R 4.5.0)
plyr 1.8.9 2023-10-02 [1] CRAN (R 4.5.0)
posterior 1.6.1 2025-02-27 [1] CRAN (R 4.5.0)
profvis 0.4.0 2024-09-20 [1] CRAN (R 4.5.0)
projpred * 2.9.0 2025-07-08 [1] CRAN (R 4.5.0)
promises 1.3.3 2025-05-29 [1] CRAN (R 4.5.0)
purrr * 1.1.0 2025-07-10 [1] CRAN (R 4.5.0)
QuickJSR 1.8.0 2025-06-09 [1] CRAN (R 4.5.0)
R6 2.6.1 2025-02-15 [1] CRAN (R 4.5.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.5.0)
Rcpp * 1.1.0 2025-07-02 [1] CRAN (R 4.5.0)
RcppParallel 5.1.10 2025-01-24 [1] CRAN (R 4.5.0)
remotes 2.5.0 2024-03-17 [1] CRAN (R 4.5.0)
rlang 1.1.6 2025-04-11 [1] CRAN (R 4.5.0)
rmarkdown 2.29 2024-11-04 [1] CRAN (R 4.5.0)
rstan 2.32.7 2025-03-10 [1] CRAN (R 4.5.0)
rstantools 2.4.0 2024-01-31 [1] CRAN (R 4.5.0)
rstudioapi 0.17.1 2024-10-22 [1] CRAN (R 4.5.0)
scales 1.4.0 2025-04-24 [1] CRAN (R 4.5.0)
sessioninfo 1.2.3 2025-02-05 [1] CRAN (R 4.5.0)
shiny 1.11.1 2025-07-03 [1] CRAN (R 4.5.0)
StanHeaders 2.32.10 2024-07-15 [1] CRAN (R 4.5.0)
stringi 1.8.7 2025-03-27 [1] CRAN (R 4.5.0)
stringr 1.5.1 2023-11-14 [1] CRAN (R 4.5.0)
tensorA 0.36.2.1 2023-12-13 [1] CRAN (R 4.5.0)
tibble 3.3.0 2025-06-08 [1] CRAN (R 4.5.0)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.5.0)
tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.5.0)
urlchecker 1.0.1 2021-11-30 [1] CRAN (R 4.5.0)
usethis 3.1.0 2024-11-26 [1] CRAN (R 4.5.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.5.0)
withr 3.0.2 2024-10-28 [1] CRAN (R 4.5.0)
xfun 0.52 2025-04-02 [1] CRAN (R 4.5.0)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.5.0)
yaml 2.3.10 2024-07-26 [1] CRAN (R 4.5.0)
[1] /Users/Erp00018/Library/R/arm64/4.5/library
[2] /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────References
Erp, Sara van, Daniel L. Oberski, and Joris Mulder. 2019. “Shrinkage Priors for Bayesian Penalized Regression.” Journal of Mathematical Psychology 89: 31–50. https://doi.org/10.1016/j.jmp.2018.12.004.
Hoerl, Arthur E, and Robert W Kennard. 1970. “Ridge Regression: Biased Estimation for Nonorthogonal Problems.” Technometrics 12 (1): 55–67. https://doi.org/10.1080/00401706.2000.10485983.
McNeish, Daniel M. 2015. “Using Lasso for Predictor Selection and to Assuage Overfitting: A Method Long Overlooked in Behavioral Sciences.” Multivariate Behavioral Research 50 (5): 471–84. https://doi.org/10.1080/00273171.2015.1036965.
Nash, Sellers, Warwick, and Wes Ford. 1995. “Abalone.” UCI Machine Learning Repository.
Piironen, Juho, and Aki Vehtari. 2017. “Comparison of Bayesian Predictive Methods for Model Selection.” Statistics and Computing 27 (3): 711–35. https://doi.org/10.1007/s11222-016-9649-y.
Footnotes
Fun fact: to determine the sex of an abalone, it is held out of the water with the holes along the bottom. The abalone will usually get tired and fall to the side so that the reproductive organ becomes visible. Females have a green reproductive organ, while males have a beige reproductive organ.↩︎
It has been shown that posterior mean estimates using the normal prior are equivalent to estimates using the traditional ridge penalty (Hoerl and Kennard 1970)↩︎
The choice of the confidence level is related to the Type 1 error rate: we choose the 95% CI to obtain a Type 1 error rate of 5%. Yet in practice, this choice is almost never made explicitly. In addition, Erp, Oberski, and Mulder (2019) have shown that the level of the CI that provides the optimal selection accuracy differs across data generating conditions.↩︎
See Piironen and Vehtari (2017) for a more detailed overview of different model selection methods.↩︎