Classical machine learning
Feature extraction inspired by human speech recognition
Scikit-learn: Feature selection
Determining number of features to select with RFE 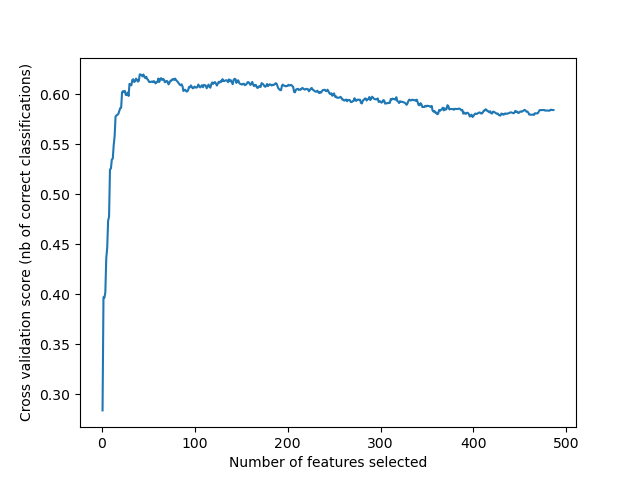
Deep learning Models
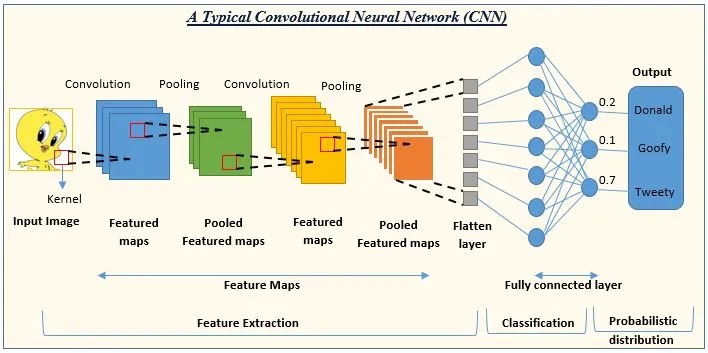
Convolutional Neural Networks (CNN)
- Convolutional layer
- Detects features e.g., edges, textures, by applying filters
- Pooling layer:
- Reduces the dimensionality of feature maps
- Fully Connected layer
- maps the features to the final output
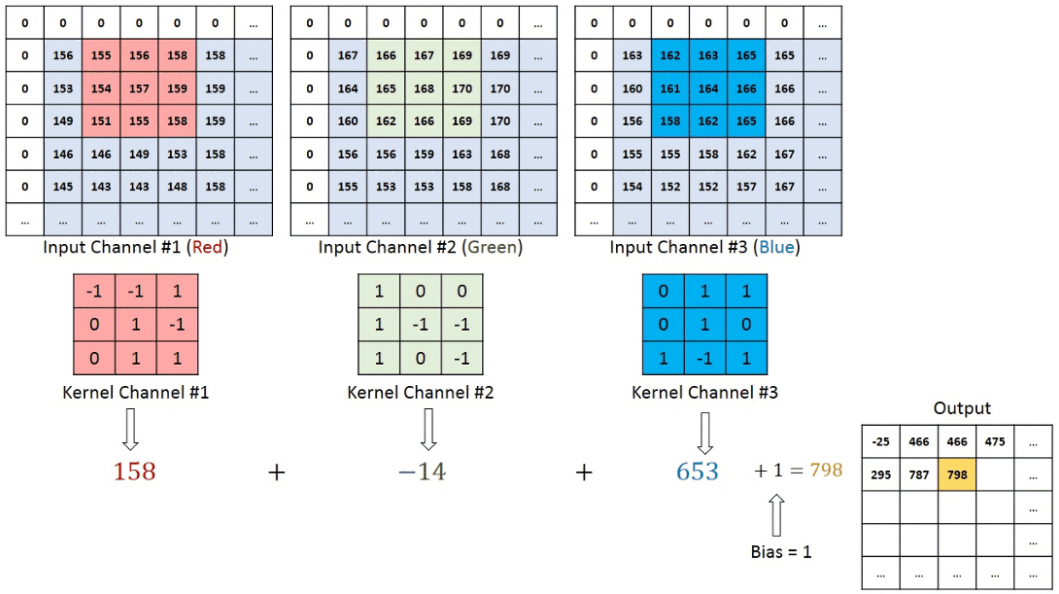
How does CNN work?
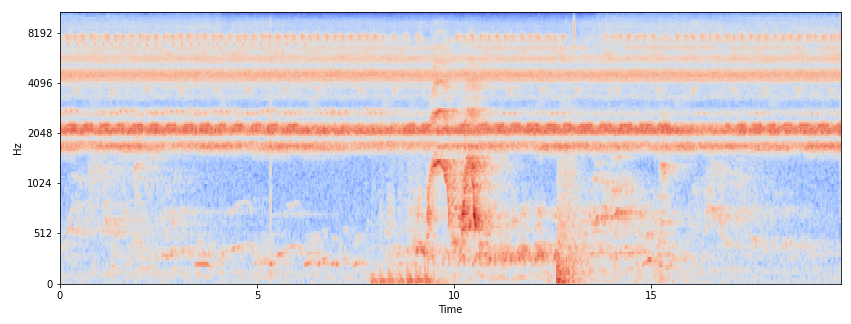
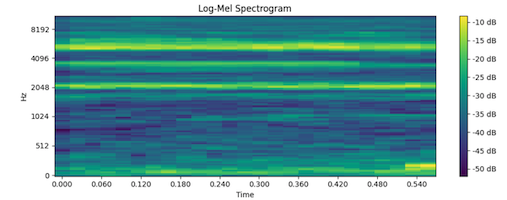
How doe we change audio to image?
Spectrogram - represents the intensity of different frequencies as they change over time, typically using a color map
Log-mel-spectrogram a variation of the standard spectrogram that applies a filter bank and a log function on top of it.
making quieter sounds more detectable.
Aligns the representation with human auditory perception
Normalizes the features
Model Architecture - Derived from PANNs
PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
designed for audio event detection and classification
a combination of convolutional blocks and pooling operations

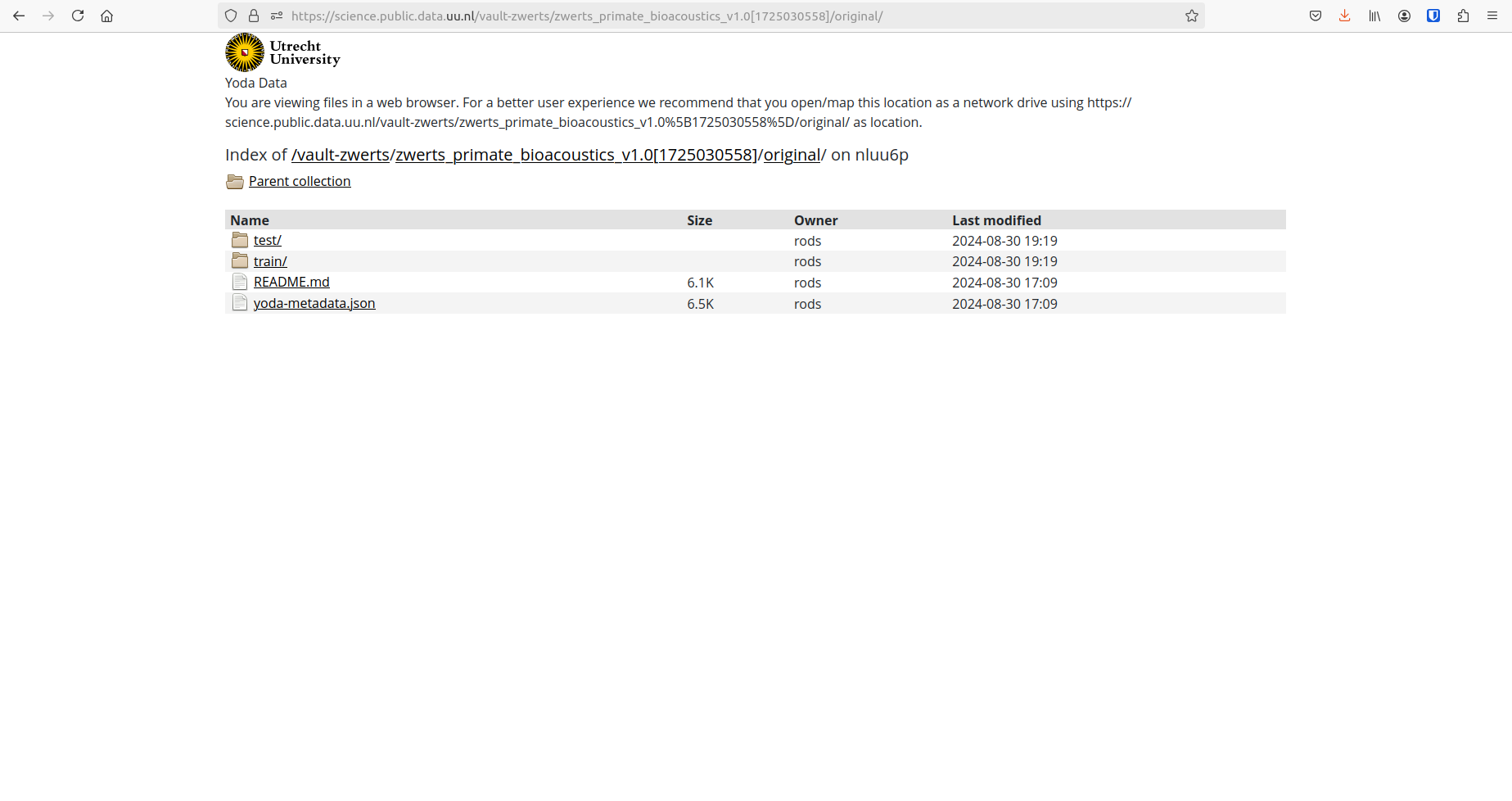
Deliverables (2/2)
Public train and test data
![]()
![]()