Privacy FAQs
Date of last review: 2023-01-27
On this page you can find Frequently Asked Questions (FAQs) about handling personal data in research. Click a question you have to read its answer.
General questions
When should I be dealing with privacy in my project?
You should think about privacy:
- as soon as you are processing personal data. Processing means anything you do with personal data, e.g., collecting, analysing, sharing, storing, etc. The definition of personal data is explained in the chapter What are personal data?.
- during the earliest stages of your project. This principle is called “privacy by design”. It is easier and more effective to address any privacy issues at the design phase of your project rather than having to change your plans later on due to privacy concerns.
When are data truly anonymous?
You can read all about this in the chapters What are personal data? and Pseudonymisation and anonymisation.
What should I consider when handling personal data?
It is best to conduct a privacy scan to check if you work with personal data. The below figure summarises what you need to describe, determine and do as part of a privacy scan: 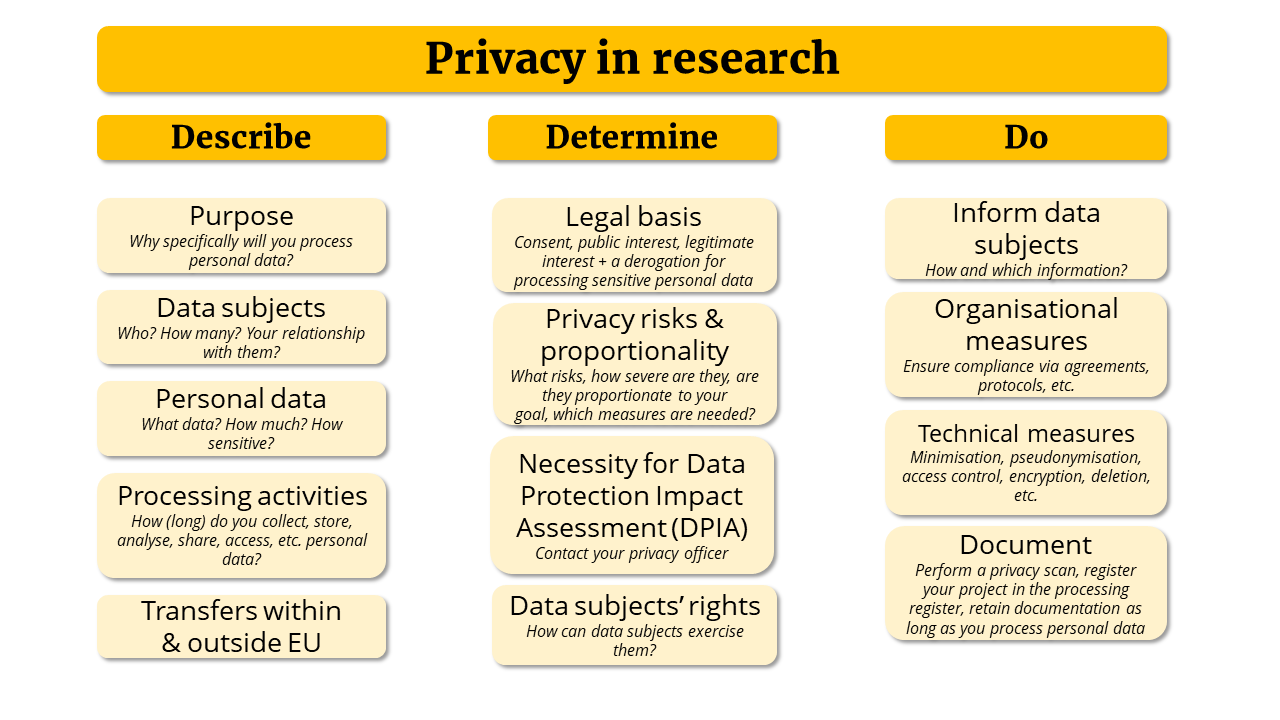
My data were collected prior to the GDPR, what rules do I need to follow?
The GDPR applies to all personal data, including those collected prior to the GDPR (May 2018). Therefore, there is really no difference between how personal data should be handled before or after the advent of the GDPR.
My data were collected outside of the EU, does the GDPR apply to them?
Yes, as long as personal data are being processed, and the data controller, data processor, or data subject reside(s) in the European Economic Area, the GDPR applies.
How sensitive are my data?
Personal data can differ in sensitivity, depending on the type of data (e.g., sensitive personal data), of whom the data were collected (e.g., healthy adults, children, patients, elderly, etc.) and on which scale. Data classification and a Data Protection Impact Assessment are useful tools to assess how sensitive the data are.
Procedures and responsibilities
Who is responsible for correctly handling personal data?
Legally, the controller of the personal data is responsible, i.e., the people or organisation responsible for the project activities. If you are an employee at Utrecht University (UU), the UU is legally the controller. The UU however delegates this responsibility to the appropriate employee who is actually in charge of determining why and how personal data are handled. In a research context, this is usually the researcher on the project (e.g., PhD candidate, principal investigator).
What does the procedure look like for researchers at Utrecht University?
All researchers at UU have to write a Data Management Plan. Besides that, many faculties require that a privacy scan is done and ethical approval is obtained. Preferably, a Data Management Plan and privacy scan (which has to sometimes be extended to a Data Protection Impact Assessment) are done (and preferably marked as positive by the relevant data steward/privacy officer) before the ethical review takes place. Once accepted by the ethical committee, you can then start your research project.
How long will the planning process of my research take?
This differs per faculty, but you should count at least 1 month, if not more, to complete all planning activities. In terms of administrative work, you need to reserve time for:
- writing a Data Management Plan and having it reviewed (a few days)
- filling out the privacy scan and consulting with the privacy officer (a few days). If a DPIA needs to be conducted, this will take more time because the Data Protection Officer also needs to be consulted.
- creating information for data subjects and potentially a consent form.
- going through ethical review: it can take up to 1 month before a first decision is taken by some faculty review boards, or longer for the Medical-Ethical Review Board.
- in some projects, setting up an agreement.
Doesn’t the ethical committee also look at privacy?
Partly, although this differs per UU faculty. In most faculties, there is a collaboration between privacy and ethics. For example, at the Faculties of Social and Behavioural Sciences, the Humanities, and Geosciences, privacy is included in the ethical application, but the privacy aspect of it is outsourced to the faculty privacy officer. For you as a researcher, it is wise to first complete a draft privacy scan, and consult with the faculty privacy officer and only then do the ethical application, so you have already thought about the privacy aspect before the ethical review process starts.
Informed consent
When is parental consent needed?
The GDPR dictates that at least one legal guardian provide consent if you process personal data from children under 16 years old. Note that for medical data and in some faculties, there can be additional requirements, such as obtaining written consent from both parents, and also from the child themselves if the child is between 12 and 15 years old.
Can consent be digital?
Yes, as long as you can demonstrate that consent was obtained, it is valid according to the GDPR. Consent can for example consist of participants ticking a checkbox in a survey tool after reading or watching information about the research. The checkbox should be empty at the start of the survey and not already come “pre-ticked”: consent must be actively given. Note that for medical data, consent may have to be provided in writing: always check with your Ethical Review Board.
Where can I find a template consent form?
You can use the minimal list of requirements for an information letter and read through the guidance on informed consent and information to data subjects. Please note that some Ethical Review Boards have specific templates that you should use.
How to balance being complete vs. being intelligible in the information to participants?
The GDPR does not require you to provide all details in the same way to participants. For example, it allows you to layer information, and it requires that you always provide the information in a format that is intelligible for your target audience, which does not necessarily have to be in text. Please refer to the section on Information to data subjects for more information on this. Please note that some Ethical Review Boards have specific requirements on how information should be provided to participants, which have to do with ethical and legal aspects other than the GDPR.
Where, how and for how long should I store my consent forms?
Consent forms have to be stored securely (access-controlled) and separately from the research data, for as long as the research data contain personal data. This can be in digital or physical (e.g., paper) form (note that paper consent forms from WMO-research are advised to be kept even after digitisation). Once the personal data are deleted or fully anonymised, the consent forms should be deleted as well. An empty consent form can be stored for longer, for example to check the phrases about re-use. Read more about this in the Data storage chapter.
A participant wants to withdraw their consent. Can I continue to use their data afterwards?
No, once a participant has withdrawn consent, you are obliged to remove any of their data that is under your control and cease any further use of their data from that point onwards. Any processing that occurred prior to withdrawal is nevertheless still legal. For example, if the data were published and made publicly available prior to their withdrawal, you are not obliged to take down the entire dataset and seek all individuals that may have downloaded the data subject’s data. Another example is if you already analysed the data (but have not yet published the results). In that case, the data have to be deleted, but you do not necessarily need to re-do the analysis. The only important thing is that the data then no longer support the analysis, so for research integrity reasons, you may want to re-do the analysis anyway.
Additionally, if you cannot find the participant’s data in your dataset because they are deidentified too much, then you are exempt from removing them, unless participants can provide you with information to enable their re-identification.
Additionally, if you cannot find the participant’s data in your dataset because they are deidentified too much, then you are exempt from removing them, unless participants can provide you with information to enable their re-identification.
Legal questions
What if I cannot formulate a specific research question in advance?
It is not always possible in research to be very specific about what the personal data will be used for in the future. In some cases, you can therefore use the concept of “broad consent”, where you continuously inform data subjects and enable them to exercise their rights. This is described in more detail here.
I will move to another institution, can I take my research data that contains personal data with me?
Moving data to another institution constitutes a new way of “processing” data and implies that there will be a new (additional) controller of the personal data. This means that you need to take some additional steps, such as ensuring that data subjects are informed about the move, the purpose of the transfer is compatible with the original purpose(s) for data use, both institutions sign an agreement on data protection, use and ownership of the data, etc. What is possible depends largely on the context of your research and the type of data you have: contact your faculty privacy officer for assistance.
When do I have to perform a Data Protection Impact Assessment?
If there is a possibility for a high risk of damages to data subjects, a DPIA is mandatory. This can for example be the case when you observe people in public spaces or process sensitive personal data on a large scale. Note that correctly performing a DPIA can take some time. Contact your faculty privacy officer if you suspect that you may need a DPIA.
Do I need an agreement?
An agreement is usually needed when someone outside of your institution accesses (personal) data that you control. Please refer to the Agreements section to assess whether you need an agreement, and if so, which type.
What is the difference between a Data Transfer Agreement and a Data Processing Agreement?
A data transfer agreement is needed when (personal) data are transferred from one controller to another, and is also recommended to use when data are transferred between departments of a single controller, to delineate the agreed upon responsibilities. For example, in research is it used often when data are shared with other researchers for reuse. A data processing agreement is needed when personal data are transferred from a controller to a processor. For example, it is needed to ensure that an external survey tool protects the university’s personal data sufficiently and does not use it for their own purposes, only to provide their survey services. You can read more about these agreements here.
Am I a processor as employee of my university?
No. As an employee you are still determining your own why (research question) and how (methods) of personal data processing. This makes you a controller, acting as an “agent” of the legal controller (your university). Read more on the difference between processors and controllers on the definitions page.
Storing personal data
Where should I store physical personal data?
Physical personal data should be stored in a locked area that only a select group of people has access to. The exact location will depend on the type of data (e.g., consent forms, filled out questionnaires, biomedical samples, etc.), and where you work. If possible, we recommend digitising and then destroying any paper materials in order to have the data in a secure and backed-up location.
Where to store participants’ contact information?
Similarly to informed consent forms, you should store contact information on a different location than the research data and well-protected (strict access control, encryption, etc.). For example, store the research data on Yoda, and the contact information in a controlled OneDrive or ResearchDrive folder. Delete the contact information when you do not longer need them (e.g., after the research project has ended).
Practical questions
I am using hardware to collect personal data. What should I take into account?
There are many security aspects to consider when using hardware (e.g., tablets, cameras, phones, etc.), such as whether and where any personal data is recorded and whether the device is approved by the university, see this link for more information. Make sure that you transfer the data to secure storage as soon as possible and consider measures (such as encryption) that ensure that data are protected if the hardware is lost or stolen. When you use video recording hardware, be mindful of what is recorded, also in the background. For example, be aware when filming around open laptops, documents or vulnerable people.
I want to combine data from multiple sources. How can I do so securely?
There are multiple factors to consider, depending on the type of research, the ownership of the data, involved parties, etc. As a rule of thumb, practice data minimisation, only keep the fields or variables you need. Be mindful of data ownership: if someone else owns the data, keep that dataset separate. For more information and tailored advice, contact RDM Support.
How to generate suitable pseudonyms?
A pseudonym can be a random number, cryptographic hash function, text string, etc. It is important that the pseudonym is not meaningful with respect to the data subjects: a random (unique) number or string is better than a code that contains parts of personal information, because the latter may reveal details about data subjects.
How to pseudonymise qualitative data?
Textual data is often redacted (either manually or using a tool so that identifiable information is removed or replaced with a placeholder text. There are now also tools for masking or blurring video data and distorting audio. Note that sometimes it is not possible to anonymise or pseudonymise qualitative data, because you may lose too much valuable information, or because the data are just too revealing (e.g., face, voice, gestures, posture in video data, language use in audio data). In that case, other measures like access control, safe storage, and encryption may be more suitable.
I am analysing my data in a git repository to ensure reproducibility. How can I make sure I do not accidentally push the data to GitHub?
Before you put your data in your git repository, place a line in the .gitignore file that prevents tracking the data. This way, when pushed to GitHub, the data will not be pushed alongside the other files in the repository - only the folder name will be visible.
Please note that if the data were tracked by git before, adding a line to your .gitignore will not prevent the data from being tracked. In this case, it is best to create a new git repository where you add a .gitignore file from the start, and delete all old versions from GitHub if there were any. If you delete the data, add the line to the .gitignore file, and then re-add the dataset, the tracking history from before the .gitignore will still exist and be pushed to GitHub.
Sidenote: it is possible to override the .gitignore file by force. This will likely not happen accidentally, but it is important to realise that the .gitignore file is not iron clad. You can read more on the gitignore here.
Please note that if the data were tracked by git before, adding a line to your .gitignore will not prevent the data from being tracked. In this case, it is best to create a new git repository where you add a .gitignore file from the start, and delete all old versions from GitHub if there were any. If you delete the data, add the line to the .gitignore file, and then re-add the dataset, the tracking history from before the .gitignore will still exist and be pushed to GitHub.
Sidenote: it is possible to override the .gitignore file by force. This will likely not happen accidentally, but it is important to realise that the .gitignore file is not iron clad. You can read more on the gitignore here.
How to securely send participant data to participants?
In the same protected way as when you would send personal data to fellow researchers. Researchers at Utrecht University can for example use SURF filesender with encryption or share a OneDrive or Research Drive file. Be sure not to share any data from other participants or other researchers!
How to work responsibly with social media data?
See these guidelines (in Dutch) about working with social media data. Every social media platform has different terms and conditions. Read these to see what you are, and are not, allowed to do with the data published on the platform you wish to research.
Where can I find relevant or approved tools?
Researchers at Utrecht University can find tools via https://tools.uu.nl and the intranet. We also curated an overview of several tools to handle personal data in this GitHub repository.
Where can I find privacy-related templates and examples for research?
Please refer to the Documents and agreements chapter or the RDM website. For others, please contact your privacy officer and/or your Ethical Review Board.
Students and student data
Can I reuse educational data (e.g., grades, course evaluations) for my research?
It is possible, but its compliance would have to be documented in a privacy scan to explain why this further processing for scientific purposes is compliant with the GDPR. Please refer to the use case about this topic for an example.
Can I share my research data containing personal data with my students?
Preferably not. Especially in a classroom setting, students should work on anonymised data as much as possible. For thesis students, only share personal data with them as strictly necessary and make sure that the students know how to safely handle the personal data. Additionally, data subjects should be informed that these students will handle their data.
Can I (re)use personal data collected by my students?
You should check what information was given to data subjects to see whether it is possible to reuse the data. In general, if data are deidentified and are going to be used for research, it is possible to make this data reuse legitimate - a privacy scan may be able to demonstrate this.
When students collect personal data, who is responsible for correct handling of those data?
The supervisor is the main person responsible, but students are also co-responsible, especially if they are taking decisions on the data themselves. Students need to comply with their respective obligations and responsibilities to ensure data is kept safe and protected.
Can a student take research data containing personal data with them to publish about them later?
It depends on why this is considered necessary, if data subjects have been informed, if data minimisation and deidentification are applied etc. If students take data with them, they will probably end up being stored on a free cloud solution such as Google Drive or Dropbox. Make sure your data subjects are informed about this beforehand and realise that obtaining consent will be more difficult. A privacy scan should document why this is compliant with the GDPR.
I am a student, where can I store my data?
If you are student who will be collecting personal data for research, it is the responsibility of your supervisor or course coordinator to supply you with access to an approved storage solution. Please do not use a personal device or commercial cloud solutions like Dropbox or Google Drive to store research data containing personal data. Any “free” commercial solution will scrape and analyse what you store and thus your data are not safe there.
Finding support
Where can I learn more?
Please see the Seeking help page for more information and contact persons for all your questions about privacy, research data management and security.
Who is the Data Protection Officer (DPO)?
The Data Protection Officer (Dutch: Functionaris Gegevensbescherming, FG) oversees an organisation’s compliance to the General Data Protection Regulation (GDPR). In research, the DPO is sometimes involved in a Data Protection Impact Assessment and in some cases in possible data breaches. If you work at Utrecht University, you can read more about the DPO’s role here.
I have a potential data breach, what should I do?
If you work or study at Utrecht University, please report this as soon as possible, preferably within 72 hours, to the Service Desk.