import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.diagnostic import het_breuschpagan
import numpy as np
import scipy.stats as stats
# read data
antlers = pd.read_csv('../Data/Antler_allometry.csv')
# apply natural log transform to the key variables
antlers['Male_mass_ln'] = np.log(antlers.Male_body_mass)
antlers['Antler_length_ln'] = np.log(antlers.Antler_length)
# sort dataframe along our desired x-axis for easier plotting of lines
antlers = antlers.sort_values("Male_mass_ln")
# rename sub family column
antlers = antlers.rename(columns={'Sub-family':"sub_fam"})
# make scatterplot of the transformed data
fig, ax = plt.subplots()
ax.plot(antlers.Male_mass_ln, antlers.Antler_length_ln, '.', color='k')
ax.set_ylabel('ln Antler length [mm]')
ax.set_xlabel('ln Body mass [kg]')
# run regression using python
model = ols("Antler_length_ln ~ Male_mass_ln", data=antlers)
model_fit = model.fit()Linear regression 2: debunking sexual selection
Introduction
Goal of today’s exercise
In the previous exercise, you have transformed the data set of antler lengths for the Irish elk (Plard et al., 2011) to remove skew from the distribution using a natural logarithm, calculated the regression line, and assessed the goodness of fit. But how good is the fit really? Was linear regression a valid approach to use for these data? Can we statistically answer the question: is deer body mass related to antler length?
Today, you’ll try to find the answers to these questions.

Parametric statistics
Parametric techniques are statistical methods that assume a specific form for the underlying population distribution. These methods often rely on population parameters (such as means and variances) that summarize the data and make certain assumptions about their structure. Linear regression is also a parametric technique, because it makes specific assumptions about the form of the relationship between the dependent and independent variables. Specifically, it assumes that this relationship can be described using a linear equation of the form:
\(y=\beta_0 + \beta_{1}x_{1}+\epsilon\)
Here, \(\beta_0\) and \(\beta_1\) are the parameters of the model, and \(\epsilon\) represents the error term. The parametric nature of linear regression means that once we estimate these population parameters from the sample data by calculating regression coefficients \(b_0\) and \(b_1\), we can use them to make predictions and perform further analysis based on the underlying assumptions of the data distribution. Particularly the assumptions about the normal distribution of the errors at any point along the x-scale is important. This means we can apply the statistical tests that are related to the normal distribution founded in the Central Limit Theorem, such as the t-test and F-test (also see Chapter 6.3–6.4 of Haslwanter, 2022).
Setup, load data, and fit regression model
Use the following code to load the data of the previous exercise and fit the regression model using ordinary least squares (OLS):
Task 1: Statistical testing in linear regression
Statistical testing (in linear regression) is all about making informed decisions based on data by systematically evaluating hypotheses, similar to other testing procedures in statistics. The core steps to follow are:
- State null and alternative hypotheses
- Choose significance level
- Select the appropriate test
- Compute test statistic using data
- Determine p-value and/or critical value for test statistic
- Make a decision on the hypothesis
Follow the above steps using the antler dataset and the model_fit to find out whether there is a statistically significant relation between antler length and male body mass. Use the two tests for this that apply to linear regression: the t-test and F-test. Follow the tips below for more information on how to perform this, refer to lecture slides on linear regression, the statsmodels package user guide, the text book (Haslwanter, 2022), and other online sources.
T-test
A t-test is used to determine whether a specific coefficient (\(\beta_i\)) is significantly different from zero. In other words, it helps to assess whether an independent variable has a meaningful impact on the dependent variable. The t-test compares the estimated coefficient to its standard error, providing a p-value that indicates the likelihood of observing such a result by chance.
You can run a t-test on the model fit simply by showing the model summary in the console.
TipQuestion 1
- Formulate \(H_0\) and \(H_A\) for a t-test of \(\beta{}_{1}\)
- Is the t-test in this case one-sided or two-sided? Briefly explain why.
- What is the test statistic value for \(\beta{}_{1}\)?
- What is the critical t value at alpha=0.05 (tip: use
scipy.stats.t.isf())?
- What is your decision on the formulated hypotheses?
ANOVA and F-test
The F-test evaluates the overall significance of the regression model. It tests whether at least one of the coefficients is different from zero, indicating that the model provides a better fit to the data than a model with no predictors. The F-test compares the explained variance of the model to the unexplained variance, yielding an F-statistic and a corresponding p-value.
Run an ANOVA on the linear regression fit to perform the F-test and inspect the results. Tip: use anova_lm().
TipQuestion 2
- Formulate \(H_0\) and \(H_A\) for an F-test of the regression
- What is the Mean Square Error (or \(\mathrm{MS_{res}}\)) for this model?
- Is the F-test one-sided or two-sided? Briefly explain why.
- What is p-value associated to the F-statistic in this case? What do you conclude from this?
- Compare this p-value to the p-value of the t-test of \(\beta{}_{1}\) (accessible using
model_fit.pvalues). What do you notice? How can this be?
Task 2: Estimating confidence intervals and belts
Confidence intervals are used to estimate the range within which a population parameter is likely to lie, based on sample data. They provide a measure of uncertainty around a point estimate with a given confidence level (\(\alpha\)). The model_fit summary provides the 95% confidence intervals of both \(\beta_0\) and \(\beta_1\).
Additionally, a confidence belt of the model fit can also be constructed, which shows where the real population mean of \(\hat{y}_i\) would lie (with \(\alpha\) confidence). Such confidence belts are often displayed on plots with regression lines. Calculate the confidence belt for the fit by using the subroutine .get_prediction() on the model_fit object, and subsequently the .summary_frame() subroutine on the prediction object.
Plot the log-transformed data again, include the regression line, annotate it with the regression equation, \(R^2\) value, p-value, and add the lower and upper limits of the confidence belt to the plot as shading. Tip: use .fill_between to create shading between two lines.
The data frame returned by .summary_frame() also provides the confidence interval for the observations, the so-called prediction interval. Add it to the plot and compare its values with the confidence interval for the mean.
TipQuestion 3
- What would it mean if the lower confidence level of \(\beta_1\) would be below zero in this case? And what if confidence interval for \(\beta_0\) would encompass zero?
- What would be the likely effect of adding more data points on the confidence intervals? Why is that?
- Why is the prediction interval wider than the confidence interval?
Task 3: Assessing validity of a linear model
A final crucial aspect of hypothesis testing is verifying that the assumptions of the statistical methods used are valid. For hypothesis tests related to linear regression to be reliable, the model’s underlying assumptions (linearity, normality of errors, homoscedasticity, and independence of errors) must be satisfied. If these assumptions are not met, the results of the hypothesis tests may be compromised. This could for instance mean that the calculations of test statistics and p-values are inflated and statistical significance is wrongfully inferred.
Using the antler data and the fitted linear model, test whether the each of the above assumptions of linear regression are met.
Linearity
Check if the relationship between the independent and dependent variables is linear.
- Plot the observed values of the dependent variable against the independent variable(s). Look for a linear pattern (straight line) rather than a curve or other non-linear patterns.
- Plot the residuals against the independent variable. For linearity, there should be no obvious patterns (e.g., curves or systematic structures). The residuals can be calculated by \(y_i-\hat{y}_i\), or taken from the
model_fitobject.
TipQuestion 4
Do you think the linearity assumption is met? Why?
Normality
To test for normality of the residuals/error, there are a few approaches possible. Try the following:
- Make a histogram of the residuals and assess its shape.
- Plot the quantiles of the residuals against the quantiles of a normal distribution, this is a so-called Q-Q plot. The points should roughly fall along a straight line 1:1 if the residuals are normally distributed. Tip: use
sm.qqplot()for this. - Apply a proper statistical test to assess normality. You can use the Shapiro-Wilk test for this using \(\alpha = 0.05\) (tip: use
scipy.stats.shapiro()).
TipQuestion 5
Do you think the normality of errors assumption is met? Why?
Homoscedasticity
To check if the residuals have constant variance (homoscedasticity) across all levels of the independent variable:
- Plot the residuals against the independent variable and assess the shape.
- Plot the absolute residuals against the independent variable and assess the shape. Now run a linear model in the form
abs_residuals ~ Male_mass_ln. Does this have a significant slope? - Run a Breusch-Pagan Test on the model using
het_breuschpagan(). As input you can usemodel_fit.resid(residuals of fitted model) andmodel.exog(independent data that was used for the OLS model). This test uses the following hypotheses:- \(H_0\): Homoscedasticity is present
- \(H_A\): Homoscedasticity is not present
TipQuestion 6
Do you think the model is homoscedastic? Why?
Independence / autocorrelation
Lack of independence of residuals/errors are an issue in linear regression. This often happens in time series data, where the value of an error term is correlated with the value of previous error terms (temporal autocorrelation), or sometimes when data are collected in space, e.g. in a single borehole or near each other in a certain x-y domain (spatial autocorrelation). Since the data in this study do not have these issues, we could skip this step for now. The steps are easy, however, and for the sake of learning to test for autocorrelation of residuals, confirm that it is absent.
To statistically test for autocorrelation (\(\rho\)) in linear regression, you use the Durbin-Watson test statistic \(d\) (see also 12.4c of Haslwanter, T., 2022.), which is simply provided by model_fit.summary2(). The values for \(d\) can range from 0 to 4, meaning:
- \(d=0\): perfect positive autocorrelation
- \(d=2\): no autocorrelation
- \(d=4\): Perfect negative autocorrelation
As a general guideline, Durbin-Watson test statistic values between 1.5 and 2.5 are considered acceptable. Values outside this range may indicate potential issues. Specifically, values below 1 or above 3 are definite causes for concern. If you want to be exact you have to look up (page 6) the critical lower (\(d_L\)) and upper (\(d_U\)) thresholds of the Durbin-Watson test statistic for a confidence level \(\alpha\) and specific combination of n (sample size, here 31) and k (number of independent variables in the model, here 1).
To statistically test for positive autocorrelation:
- If \(d < d_L\), there is statistical evidence that the error terms are autocorrelated
- If \(d > d_U\), there is no statistical evidence that the error terms are autocorrelated
- If \(d_L < d < d_U\), the test is inconclusive.
To statistically test for negative autocorrelation:
- If \((4-d) < d_L\), there is statistical evidence that the error terms are autocorrelated
- If \((4-d) > d_U\), there is no statistical evidence that the error terms are autocorrelated
- If \(d_L < (4-d) < d_U\), the test is inconclusive.
TipQuestion 7
The test is inconclusive, but theoretically there should be no autocorrelation in these data. How can this be?
Combining the results of the tests you performed on the regression result, answer the following question.
TipQuestion 8
Are the assumptions of linear regression met sufficiently to validate the use of linear regression?
Task 4: Revisiting deer
One reason for the invalidity of the model could be the interplay between other independent variables that may be significantly controlling antler length and are not taken into account in your current model. For example, in the dataset by Plard et al. (2011) there are three sub families of deer, which may scale differently (Tsuboi et al., 2022): Muntiacinae (Muntjacs), Odocoileinae (“New World Deer”) and Cervinae (“Old World Deer”). Some examples of different species in these three sub families are shown below.
_male_head.jpg)


You can easily display the different sub-families in a plot using the seaborn plotting engine:
sns.scatterplot(
x = "Male_mass_ln",
y = "Antler_length_ln",
hue = "sub_fam",
style = "sub_fam",
data = antlers)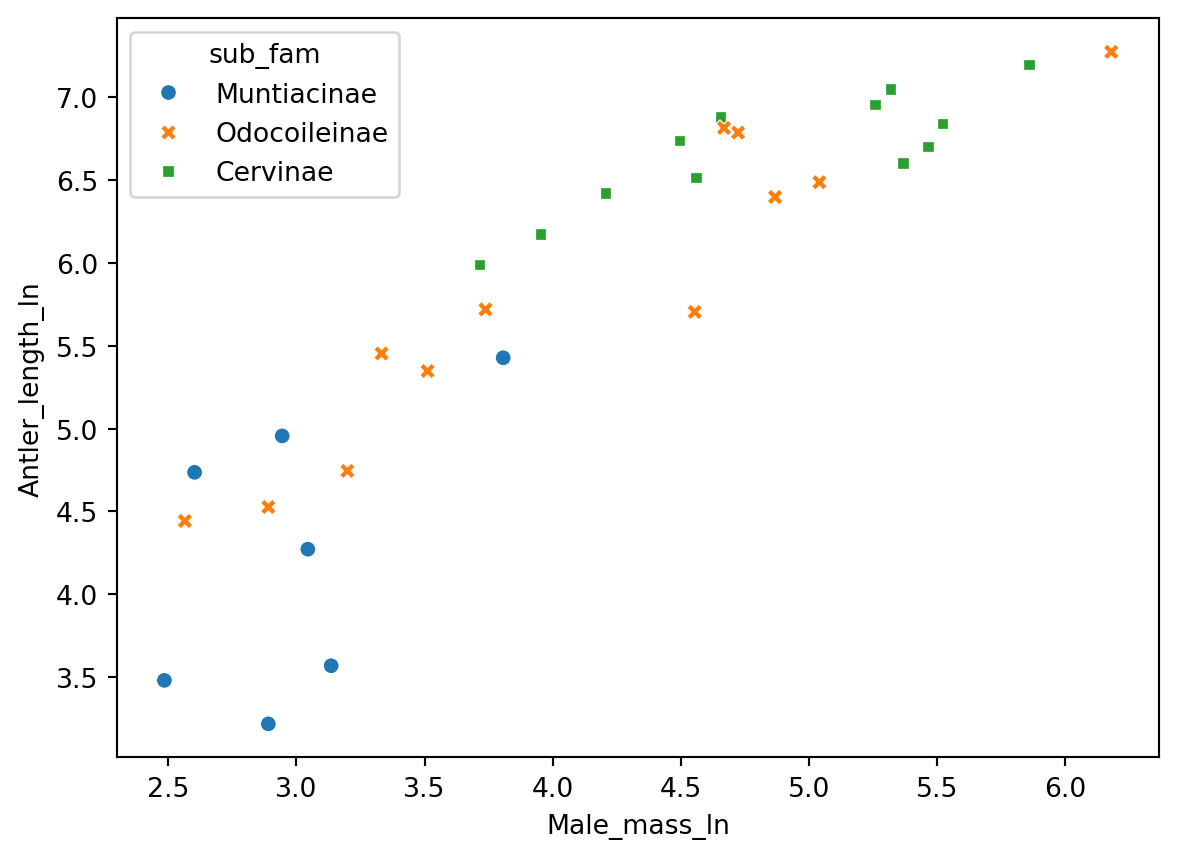
From the log-log plot, it seems that particularly the sub-family Muntiacinae appears to deviate from the linear pattern in the entire sample.
Filter antlers and only run the linear regression on a combined sample of the sub-families Odocoileinae (“New World Deer”) and Cervinae (“Old World Deer”). Check whether the expected relation between body mass and antler length holds when not considering Muntiacinae by applying the necessary parts of the above procedure to the filtered data.
antlers_fltr = antlers[antlers["sub_fam"] != "Muntiacinae"]
TipQuestion 9
- Has the model improved?
- Are the assumptions for linear regression met in this case?
Perform the procedure once more, but now separately for both subspecies of Odocoileinae and Cervinae.
TipQuestion 10
Are the assumptions for linear regression met in both these cases?
An interesting scientific question could be whether the relations between body mass and antler length differ significantly between different the sub families. In statistics, when the relations between two (or more) variables depend on another variable, it is called an interaction effect.
In this example, one could say: does antler length increase by a certain amount (i.e. slope of interaction effect) more per body mass unit for Odocoileinae than Cervinae? To test this hypothesis, we need to add the relevant interaction term to the model. In this case, we’ll include the interaction term Male_mass_ln * Sub-family (for more details on interaction formulations see 12.2.4 of Haslwanter, 2022).
model_comp = ols("Antler_length_ln ~ Male_mass_ln * sub_fam", data=antlers_fltr)
model_comp_fit = model_comp.fit()
print(model_comp_fit.summary2())The p-value for slope of the interaction term (the term that includes both the predictor and the group variable) indicates whether the two groups are statistically different. If the p-value is less than your predefined \(\alpha\), you can reject the null hypothesis that the slopes are equal, i.e. the slopes are significantly different.
TipQuestion 11
Do the two sub families that you’ve tested have a different allometric relation between body mass and antler length?
References
- Haslwanter, T., 2022. An Introduction to Statistics with Python: With Applications in the Life Sciences, Second. ed, Statistics and Computing. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-97371-1
- Plard, F., Bonenfant, C., Gaillard, J.-M., 2011. Revisiting the allometry of antlers among deer species: male–male sexual competition as a driver. Oikos 120, 601–606. https://doi.org/10.1111/j.1600-0706.2010.18934.x
- Tsuboi, M., Kopperud, B.T., Matschiner, M., Grabowski, M., Syrowatka, C., Pélabon, C., Hansen, T.F., 2024. Antler Allometry, the Irish Elk and Gould Revisited. Evol Biol 51, 149–165. https://doi.org/10.1007/s11692-023-09624-1